

こんにちは、スクーティー代表のかけやと申します。
弊社は生成AIを強みとするベトナムオフショア開発・ラボ型開発や、生成AIコンサルティングなどのサービスを提供しており、最近はありがたいことに生成AIと連携したシステム開発のご依頼を数多く頂いています。
Reflexionという手法が注目されています。LLMの出力の精度を上げる有効な手法のようです。
簡単に言うとLLMの出力を別のLLMが評価し、その評価結果を元に改善点をLLMが言語化し、その改善点に従って生成したコンテンツを修正するというものです。
Reflexionは仕組みとしてはシンプルなので、Difyのワークフローで再現し、出力を検証してみました!

Reflexionとは

Reflexionは、従来の強化学習(RL)とは異なり、エージェントの重みやパラメータを調整するのではなく、言語によるフィードバックを用いて自己改善を行う新しい学習フレームワークです。
具体的には、エージェントがタスクを実行する際に得られるフィードバック(成功・失敗など)を言語的に反映し、その内容をメモリに保存します。これにより、次回以降の試行でより良い意思決定が可能になります。この仕組みは、人間が失敗から学んで行動を改善するプロセスに類似しています。
論文はこちらです。
技術的な仕組み
Reflexionは、主に3つのモデルを組み合わせて実現されます。
Actorモデル: これはエージェントとして動作する言語モデル(LLM)であり、タスクを実行します。エージェントは、環境からの状態(観測結果)に基づいて、テキストやアクションを生成します。例えば、コードの生成や、ゲーム内での行動選択などが含まれます。このモデルは従来のRLと同様に、ポリシー(πθ)に基づいて行動選択を行います。
Evaluatorモデル: Actorが生成した結果(コードや行動など)を評価します。この評価は、例えば、プログラミングタスクであれば、生成されたコードが正しく動作するかどうかをテストします。これにより、エージェントの行動に対する報酬(成功/失敗)が与えられます。
Self-Reflectionモデル: このモデルがReflexionの中心となる部分で、フィードバックをもとにエージェントが次の行動に向けた改善点を文章化します。例えば、「前回の試行ではコードが正しく動作しなかったが、その原因は関数の入力を誤って処理していたためである」といった具体的な反省文を生成し、それを次回の試行時の参考としてメモリに保存します。これにより、エージェントは自分自身の失敗や成功を理解し、それに基づいて自己改善を行うことが可能です。
実現方法
エージェントの学習ループ: Reflexionは、タスクが成功するまで複数の試行を行い、その都度フィードバックを反映します。例えば、コード生成タスクでは、エージェントはまず関数を生成し、その後Evaluatorがその関数を評価します。評価結果に基づき、Self-Reflectionモデルがフィードバックを生成し、エージェントが次回の試行で行動を改善します。このループは、エージェントが正しい解を見つけるまで繰り返されます。
短期・長期メモリの使用: Reflexionでは、エージェントが「短期メモリ」と「長期メモリ」の2つのメモリを利用します。短期メモリには直近の試行のフィードバックが保存され、長期メモリにはエージェントの全体的な学習履歴が蓄積されます。これにより、エージェントは過去の試行結果に基づいてより洗練された行動選択ができるようになります。
フィードバックの言語化: Reflexionの特長は、数値的な報酬ではなく、自然言語でのフィードバックを用いる点です。エージェントが行った具体的なミスや改善すべき点を自然言語で記録するため、より柔軟で具体的な自己改善が可能となります。これにより、単なる「成功/失敗」といった二値の評価だけでなく、詳細な行動修正が可能です。
DifyでReflexionを再現する
Difyとは
Difyを使えばプログラムを書かずに簡単にフィードバックの仕組みを作れるため、DifyでReflexionっぽいものを再現し、動作を見てみようと思います。
Difyについては以下の記事をご覧ください!
- Difyってなに?という方:DifyでSEO記事作成を試してみる
- Difyでワークフローの作り方:Difyのワークフローを使って今度こそSEO記事を作成する【2024年6月更新】
Difyの環境構築方法やバージョンアップ方法は本家のレポジトリを参照することをおすすめします。特にバージョンアップ方法はバージョンごとに微妙に方法が変わってきているため、最新版を確認する必要があります。
本記事の検証は、MacOSのローカルPC上に、Dify v0.7.3で検証しましたが、特にこのバージョンでないと使用できない機能を使用しているわけではありません。
Reflexionを検証するワークフローを作成する
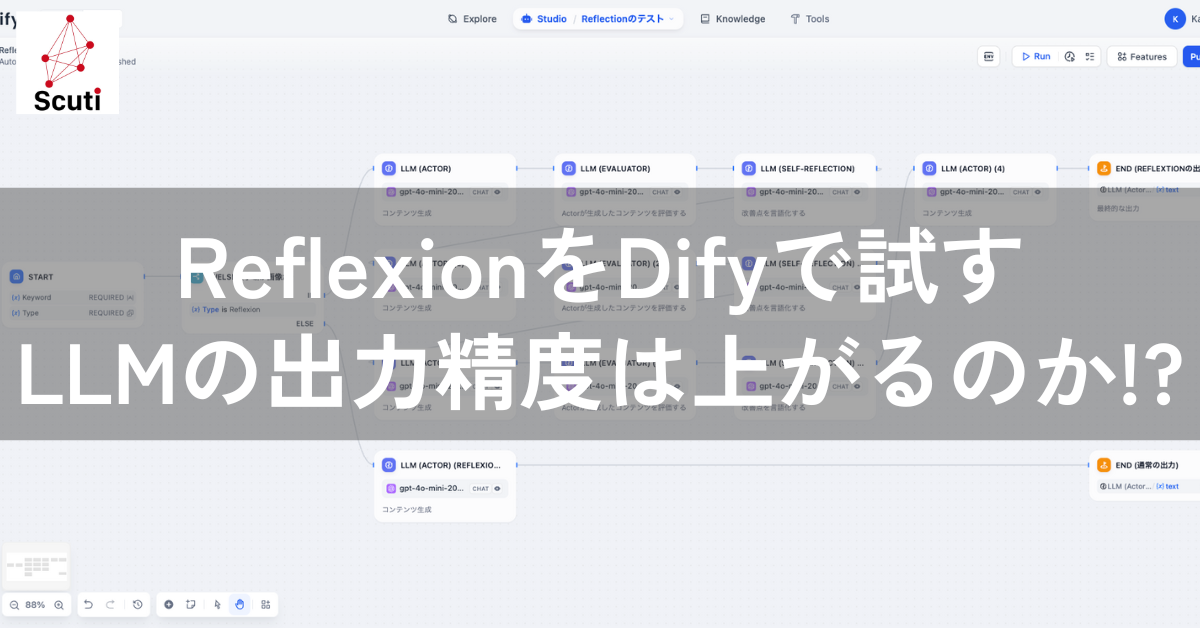
今回Dify上に作成したワークフローは以下のようなものです。あまり特別なことはしておらず、上記のActor(コンテンツ生成)、Evaluator(生成されたコンテンツを評価)、Self-reflection(評価に基づいて改善点を言語化する)に相当するステップをLLMで作成し、それらを数珠つなぎにして3セット作成しました。
本来は、Evaluatorで評価した結果、〇〇の項目が△△点以上になるまで生成→評価→改善点を言語化という処理のセットを繰り返すのが望ましいですが、DifyではプログラムのWhile構文のようなものが作れないため、今回はとりあえず3回繰り返すという風にしています。

やってることはわかるけど、ワークフロー作るの面倒そう、、、という方、Difyの構築、初期設定、Agentやワークフロー構築、運用保守などをまるっとお任せいただけますので、ぜひお気軽にご連絡ください!
今回の検証は、あるキーワードに関連する小噺をLLMに作成させ、通常のLLMの出力と、Reflexionの場合とで出力がどのように変わるかを比較しました。
ポイントだけ以下に詳細を記載します。
Step.1 質問を入力
ここではキーワードを入力し、タイプを選択するようにしています。
タイプと言うのは、LLM単体かReflexionかを選択するものです。検証しやすいようにしただけのもので、特に重要なものではありません。
Step.2 条件分岐
Step.1で入力されたタイプによって、LLM単体の処理にするか、Reflexionの処理にするかを分岐しています。
Step.3-a Actorの処理(初回のコンテンツ生成)

ここで入力しているプロンプトは上記のスクリーンショットのとおりですが、キーワードをテーマにした小噺をオチを付けて作成してもらっているだけです。モデルは速く処理を終わらせられるようにGPT-4o miniにしています。
Step.4 Evaluatorの処理(生成したコンテンツの評価)

Step.3-aで出力された小噺バージョン1をこのStepの入力にし、その小噺をある評価基準に基づいて10段階評価で評価してもらい、フィードバックをしてもらうようなプロンプトを実行しています。
Step.5 Self-reflectionの処理(評価を元に改善点を言語化)

Step.3-aで生成された小噺と、Step.4で生成された評価結果を入力にし、小噺をどのように修正すべきかを出力してもらいます。
Step.6 Actor(改善点に従ってコンテンツを修正)

Step.3-aで生成した小噺と、Step.5で出力した改善点を入力にし、小噺を改善点に従って改善してもらいます。
以降は、Evaluator→Self-reflection→Actorの繰り返しです。この一連の流れを3回繰り返した後にワークフローの出力とします。
Step.3-b Actorの処理(初回のコンテンツ生成)

ここはLLM単体での処理の場合のActor部になりますが、Step.3-aと全く同じ処理です。ただし、このStepの処理をそのままワークフローの出力とします。
設定方法はわかったけど、これを業務に活用できる場面がよくわからないし、設定が面倒そう、、、と感じましたか?確かに、実際私が上記の設定をする際も色々動作確認しながらだったので、結構たいへんでした。。。
もし、Difyの環境構築、設定、諸々まるっと任せてしまいたいというご要望ございましたら、お気軽にご連絡ください!
LLM単体とReflexionの出力を比較する

上記に説明した通りの処理を実行し、LLM単体の場合とReflexionの場合で、生成された小噺がどのように変わるかを比較しました。
処理時間に関して
当然ですが、処理時間はReflexionのほうが長くかかります。
上記のスクリーンショットに表示されていますが、GPT-4o miniの場合、1ステップあたりだいたい10秒程度かかっており、全部で2分弱かかりました。
1回検証する目的であればこの長さはさほど気になりませんが、繰り返しやる業務にReflexionを使用するのであれば、もっと処理速度は速いほうがいいでしょう。
そのために私はGroq(Llama3.1)を使用してみたのですが、何度実行してもRate limitに引っ掛かり(恐らく1分あたりのトークン数)最後まで実行を完了することができませんでした。
GroqのRate limitを拡大するには、APIのプランをDeveloperプランなるものにすれば良さそうなのですが、Developerプランは「Coming soon」になっていて使えませんでした。
仕方なく今回はGPT-4o miniでやってしまいました。
結果の比較
私の経験上、GPT-4oはお笑いのセンスがないので、我ながらなぜ小噺というテーマを選んでしまったのか謎なのですが、今回もこのテーマのせいで微妙な結果になりました。
▼Reflexionの結果
ある日、友人の太郎と次郎が公園のベンチでおしゃべりをしていた。
太郎「最近、うちの猫がツンデレでさ。」
次郎「ツンデレ?猫がそんなことするのか?」
太郎「そうなの。普段は全然寄ってこないのに、俺が寝てるときだけ、急に膝に乗ってくるんだ。」
次郎「それは可愛いじゃないか。」
太郎「可愛いと思うだろ?でも、目が覚めた瞬間、猫が『何見てんのよ!』って顔して、すぐに逃げちゃうんだ。」
次郎「完全にツンデレだな!」
太郎「おやつをあげようとすると、最初は無視して、『別にあなたのために食べるんじゃないから』って感じで、ちょっとだけ振り向く。」
次郎「それ、俺たちみたいだな。」
太郎「俺たち?」
次郎「だって、お前が『遊ぼう』って言うと、最初は『別にお前と遊びたいわけじゃないけど』って思うから。」
太郎「確かに、そういうこともあるな。」
次郎「で、アニメの声真似を試みたって?」
太郎「ああ、俺が『にゃーん!おやつあげるよ!』って言うと、最初は全然無関心だったけど、ある日、猫がふっと振り返ったんだ。」
次郎「それ、どんな顔してた?」
太郎「『今さら私に気づいたの?』って、まるで人間のような目で!」
次郎「その後は?」
太郎「また『にゃーん』って言った瞬間、猫がすぐに来て膝に乗った。でも、目を開けたら、『何見てんのよ!』って言って逃げた。」
次郎「猫のツンデレは最高だな!」
太郎「最近は、猫が膝に乗ると、目を閉じて『いい夢を見てる』と思い込むことにした。」
次郎「でも、目を覚ましたら猫がいなくなったらどうする?」
太郎「それが、今度は夢の中で猫に『にゃーん』って言ってみることにしたんだ。」
次郎「夢の中の猫がツンデレだったらどうする?」
太郎「その時は猫に『お前は夢の中でもツンデレかよ!』って言うさ。」
次郎「夢の中の猫が『現実よりマシだから』って答えたら?」
太郎「それは面白いけど、夢の中で猫に振り回されるのも嫌だな。」
次郎「まさに猫の思う壺だな。」
太郎「でも、最近思ったんだ。猫もツンデレだけど、俺もツンデレかもしれないって。」
次郎「お前が?」
太郎「だって、膝に乗ってくる猫に心の中では『可愛い、もっと来い!』って思いながら、『何見てんのよ!』って言ってるから。」
次郎「それ、完全にツンデレだな!」
太郎「だから、俺も猫に負けないように、もっとツンデレになってみようかと思って。」
次郎「お前がツンデレになったら、猫が『何それ、意味不明』って逃げるかもな。」
太郎「そうかもしれないな…でも、結局、ツンデレ猫と仲良くなるためには、互いにツンデレを楽しむことが一番だよな。」
次郎「なるほど、最終的には良いカップルになれるってことか。」
太郎「でも、猫が夢の中で『にゃーん』って言ってくるのは勘弁だな。」
次郎「それ、まさにツンデレの極みだな!」
太郎「じゃあ、次は夢の中で『お前は俺の夢の中で一番のツンデレだ』って言ってみるよ。」
次郎「それ、猫には通じないだろうけど、夢の中の猫が『それなら、もうちょっと優しくしてよ』って言ってきたらどうする?」
太郎「その時は、目を覚ます前に、猫に『夢の中の方が優しいじゃん』って言っておくよ。」
次郎「お前、相当ツンデレだな。でも、いい夢を見たら、少しスッキリするかもしれないな!」
太郎「じゃあ、次は一緒に夢の中で猫とツンデレごっこやろうぜ!」
次郎「それ、猫が『何それ、意味不明』って言ったらどうする?」
太郎「その時は、夢の中で『お前が一番のツンデレだ』って言ってやるさ。」
次郎「結局、猫に振り回されるのはお前の運命ってわけだな!」
太郎「それが、ツンデレの宿命さ!」
すると、その時、猫が二人の会話を聞いていたのか、突然現れて、太郎の膝に乗った。その直後、猫は太郎の顔をじっと見つめて言った。
猫「ねえ、そんなこと考えてる暇があったら、もっとおやつくれない?」
太郎と次郎は大笑いしながら、公園を後にした。結局、ツンデレ猫と人間の関係は、互いに少しずつ心を開くことで、より愛らしくなるのだと感じたのだった。
▼LLM単体の結果
ある日のこと、友人のタケシとサトシが公園のベンチに座り、昼下がりの陽射しを浴びながら話をしていた。
タケシ:「なあ、最近ツンデレの猫を飼い始めたんだよ。」
サトシ:「ツンデレの猫? それ、どういうことだ?」
タケシ:「いや、最初は全然近寄ってこないし、俺が近づくと『何よ、あんたなんか嫌いよ!』って感じで目をそらすんだけど、ふとした瞬間に甘えてくるんだ。」
サトシ:「なるほど、ツンツンしてるかと思えば、デレデレになるわけだ。」
タケシ:「そうそう! 例えば、俺がソファに座ってると、最初は遠くでじっと見てるんだ。でも、少し目が合うと急に『あんたのことなんて、別に気にしてないから!』みたいに、急いで別の部屋に行っちゃうんだ。」
サトシ:「でも、その後はどうなるの?」
タケシ:「その後、気配を感じて振り返ると、いつの間にか俺の足元にいるんだ。まるで、気づかれないように忍び寄ってくるみたいに。」
サトシ:「それ、完全にツンデレだね! でも、そんな猫をどうやってなつかせたの?」
タケシ:「実は、最初は何をしてもダメだった。でも、ある日、猫が好きな魚の缶詰を開けたら、急に顔を出してきて…」
サトシ:「おお、さすが食いしん坊!」
タケシ:「そう、でもそのときも一瞬、俺のことを『ちょっと、そんなの期待してないから!』って顔してたけど、缶詰の匂いに負けて、『あんた、いいかもね』って感じで近づいてきたんだ。」
サトシ:「その瞬間、猫の心をつかんだわけだ!」
タケシ:「そうなんだ。で、その後、毎晩同じ時間に缶詰を開けると、最初は『またあんたか』ってツンツンしてるけど、結局は『私が来てあげたんだから、感謝しなさいよね』って感じで、すぐにデレデレになるんだ。」
サトシ:「そんな猫、可愛いな! でも、ツンデレすぎて、ちょっと面倒じゃない?」
タケシ:「確かに。でも、ある日、猫が俺の膝に乗ってきたとき、思わず『おお、やっとデレたか!』って言ったら、急に『何言ってるの、私はただ居心地がいいだけよ!』って顔して、また逃げちゃった。」
サトシ:「それ、猫のツンデレの極みじゃん! でも、そういうのが楽しいんだろう?」
タケシ:「まさに! でも最近、猫が本当にデレデレになる瞬間があって…。」
サトシ:「何それ? もしかして、もう一つ缶詰をあげたとか?」
タケシ:「いや、俺が風邪ひいて寝込んでたとき、いつもは無関心なのに、なぜかずっとそばにいてくれたんだ。おかげで、すっかり元気になって…。」
サトシ:「それって、ツンデレを超えた愛情表現だね!」
タケシ:「そう思うだろ? でも、俺が元気になると、すぐに『もう、あんたが元気になるなんて期待してないから!』って言わんばかりに、またどこかへ行っちゃった。」
サトシ:「結局、ツンデレって猫の永遠のテーマなんだね。」
タケシ:「そうそう。結局、ツンデレの猫ってのは、愛情とツンツンのバランスが絶妙なんだよ。まるで、映画のエンディングみたいにスッキリするけど、最後まで期待を裏切られるっていうね!」
サトシ:「それが猫の魅力か! でも、たまには素直に甘えてくれたらいいのにな。」
タケシ:「ああ、でもそれじゃあ、ツンデレの猫じゃなくなっちゃうからね。ツンデレがあるからこその楽しみってやつだ!」
サトシ:「結局、ツンデレの猫は猫のままでいいってことか!」
タケシ:「そう、だから俺は今日も缶詰を開けるんだ。『あんたなんか嫌いよ!』って言われながらも、猫の真実の愛に期待しつつね!」
二人は笑い合い、日が暮れるまで猫の話に花を咲かせるのであった。
ちなみにキーワードは「ツンデレの猫」で、Evaluatorでの評価項目は下記です。
- おもしろさ(笑えるかどうか)
- オチの衝撃度
- 読後感
- 独創性
- インテリジェンス
さて、小噺の出来栄えの比較なのですが、、、Reflexionのほうが若干いいんですかね・・・?
まず、両者とも長すぎ(800〜1000文字で指定したのに1500文字くらいある)、オチがなく、笑いどころがさっぱりわかりません。
しかし、後者はただ2人の会話が繰り返されるだけの、これ以上ない退屈な文章ですが、前者(Reflexion)のほうは、ほのかなストーリーめいたものと、オチを作ろうとした形跡のようなものが見て取れます(まさか、猫が喋ったというオチではないと思います)。
・・・というかなり苦しい理由でReflexionのほうが出力の精度はいいと感じますが、もう少しちゃんと評価項目を選んだり、フィードバックのやり方を工夫すれば、LLMの出力の精度を上げられそうな体感は得られました。

