

こんにちは、スクーティー代表のかけやと申します。
弊社は生成AIを強みとするベトナムオフショア開発・ラボ型開発や、生成AIコンサルティングなどのサービスを提供しており、最近はありがたいことに生成AIと連携したシステム開発のご依頼を数多く頂いています。
近年のAI技術の進歩は目覚ましく、特に自然言語処理の分野では、大規模言語モデル(LLM)の登場により、様々なタスクで人間を凌駕するパフォーマンスを発揮するようになりました。しかし、LLMは学習データに存在しない知識を扱うことが苦手であり、最新の情報や特定のドメイン知識を必要とするタスクでは、その性能が制限されてしまうという課題がありました。
この課題を解決する手法として、Retrieval-Augmented Generation (RAG) が大きな注目を集めています。RAGは、外部の知識ベースから関連する情報を検索し、それを基にLLMが応答を生成する手法です。しかし、RAGにも課題は存在します。リアルタイムな情報検索に伴う遅延、関連文書を正確に選択することの難しさ、そしてシステム全体の複雑さなどが挙げられます。
これらの課題を克服する可能性を秘めた新たな手法が、Cache-Augmented Generation (CAG) です。CAGは、事前に計算したKey-Valueキャッシュを利用することで、RAGの課題を解決し、より高速かつ効率的な応答生成を実現する可能性を秘めています。
この記事では、CAGの仕組み、RAGとの違い、そしてそのメリットとデメリットについて、詳細に解説します。

RAGとCAG、2つの知識活用アプローチ
RAGの基本構造とそのメリット・デメリット
Retrieval-Augmented Generation (RAG)は、LLMの能力を拡張する強力なアプローチとして注目されています。RAGは、質問応答システムや文書要約など、外部知識を必要とするタスクにおいて、LLM単体よりも優れた性能を発揮します。RAGの基本的な仕組みは、ユーザーからのクエリを受け取ると、まず関連する文書を外部の知識ベースから検索します。そして、検索された文書をコンテキストとしてLLMに入力し、応答を生成します。
RAGのメリットは、LLMが学習データに含まれない知識を活用できる点にあります。例えば、最新のニュース記事や、特定の専門分野に関する文書など、LLMが事前に学習していない情報を基に応答を生成することが可能です。また、検索された文書を根拠として応答を生成するため、LLM単体で問題となるハルシネーション(事実に基づかない応答)を抑制する効果も期待できます。
しかし、RAGにはいくつかのデメリットも存在します。まず、リアルタイムに文書を検索する必要があるため、応答生成に遅延が生じます。特に、大規模な知識ベースを扱う場合、検索に時間がかかり、ユーザー体験を損なう可能性があります。また、関連する文書を正確に選択することが難しく、無関係な文書がコンテキストに含まれてしまうと、応答の品質が低下します。さらに、文書検索システムとLLMを組み合わせる必要があるため、システム全体の複雑さが増し、開発や運用にコストがかかります。
RAGについてはこちらの記事に詳細を記載していますので、ぜひご覧ください!
関連記事:【生成AI】RAG(Retrieval Augmented Generation)とは?LLMの回答精度を向上させる技術

CAGの革新性:キャッシュによる高速化と高精度化
Cache-Augmented Generation (CAG)は、一言でいうと、よく使う情報を「キャッシュ」に保存しておくことで、AIの応答を速く、正確にする技術です。従来のRAGという方法では、AIが質問に答えるたびに、毎回インターネットで情報を検索していました。これは、例えるなら、毎回図書館に行って、必要な本を探してから、答えを導き出すようなものです。当然、時間もかかりますし、適切な本が見つからなければ、正しい答えにたどり着けません。
CAGでは、この問題を解決するために、「キャッシュ」という仕組みを導入しました。これは、よく使う情報を、あらかじめAIの近くに保存しておく、いわば「カンペ」のようなものです。AIは質問を受けると、まずこの「カンペ」を見に行きます。もし「カンペ」に答えがあれば、すぐに回答できます。もしなければ、従来通り、インターネットで情報を検索します。
この「カンペ」があるおかげで、CAGはRAGよりも、以下の点で優れています。
- 速い: 毎回情報を検索する時間と手間が省けるため、AIはより速く応答できます。
- 正確: あらかじめ関連性の高い情報を「カンペ」に保存しておくことで、間違った情報や関係のない情報を選んでしまうリスクを減らし、より正確な応答が期待できます。
- シンプル: 情報を検索するシステムが不要になるため、システム全体をシンプルにでき、開発や運用が楽になります。
つまり、CAGは、AIをより速く、正確に、そして効率的にするための、革新的な技術なのです。

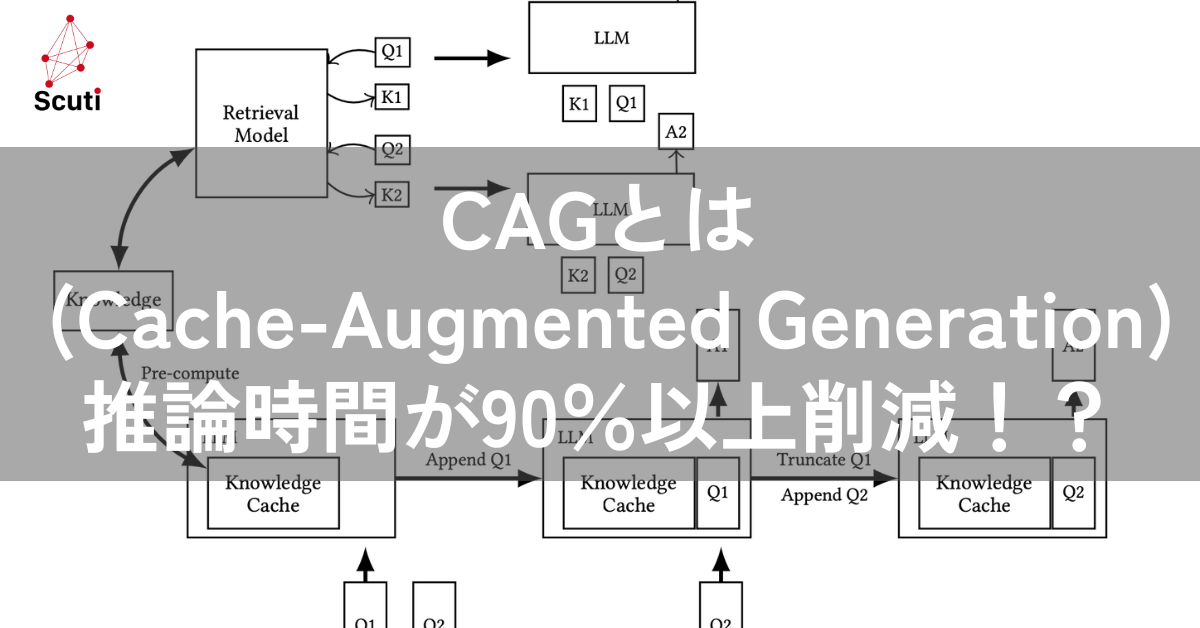
上記の図は、RAGとCAGのワークフローを比較したものです。この図から、RAG(上段)とCAG(下段)の推論プロセスの違いが一目でわかります。
RAGでは、ユーザーからの質問(Question 1, Question 2)があるたびに、毎回データベースから関連情報を検索し、その情報と質問を組み合わせてLLMに入力し、回答を生成しています。
一方、CAGでは、事前に計算されたKVキャッシュ(Knowledge Cache)を利用するため、推論時に毎回情報を検索する必要がありません。ユーザーからの質問は、KVキャッシュと組み合わせてLLMに入力され、回答が生成されます。つまり、CAGでは、RAGで必要だった「Retrieval」のステップが省略されているのです。これにより、CAGはRAGよりも高速に応答を生成することができます。 RAGでは推論時に毎回、リアルタイムな情報検索が必要となりますが、CAGでは事前に計算したKVキャッシュを利用するため、その必要がありません。
CAGはこちらの論文で紹介されています。
関連資料:Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks
CAGの詳細なメカニズム
知識の事前処理とKVキャッシュの生成
CAGでは、まず、LLMが扱う知識ベース全体を事前に処理します。具体的には、知識ベースに含まれる各文書をLLMに入力し、各文書に対するKey-Value (KV) キャッシュを計算します。このKVキャッシュは、LLMの内部状態、つまり、アテンション機構におけるキーとバリューの値を保存したものです。
ここで、アテンション機構について簡単に説明します。アテンション機構は、LLMが入力されたテキストのどの部分に注目すべきかを判断するためのメカニズムです。アテンション機構では、クエリ、キー、バリューという3つの要素が用いられます。クエリは、現在の処理対象となる単語やフレーズを表し、キーは、クエリと関連する情報を検索するためのインデックス、バリューは、キーに対応する実際の情報です。
下記の図は、Transformerにおけるアテンションの計算部分を抜き出して図示したものです。この図は、”Attention is All You Need” という論文で提案されたTransformerモデルの中核となるアテンション機構の計算プロセスを示しています。具体的には、クエリ(Query)、キー(Key)、バリュー(Value)という3つの要素がどのように相互作用して、最終的な出力(Scaled Dot-Product Attention)を生成するのかを視覚的に表しています。
まず、単語やフレーズの埋め込み表現が、一番下の「Q」「K」「V」と書かれた矢印から入力され、それぞれ「Query」「Key」「Value」に変換されます。その後、「MatMul」(行列乗算)でQueryとKeyの関連度を計算し、「Scale」(スケーリング)で過剰な重み付けを調整、「Mask」(マスキング、オプション)で不要な情報を除外し、「Softmax」で正規化することで、最終的にどのValueに注目すべきかの重み(Attention)を計算します。そして、その重みに基づいてValueを重み付け平均することで、「Scaled Dot-Product Attention」という形で、文脈を考慮した情報が出力されます。
この一連の計算により、モデルは入力された情報の中で、どの部分に注目すべきかを判断し、それに基づいて応答を生成します。この図の右側にある「Multi-Head Attention」は、この「Scaled Dot-Product Attention」を複数並列に行うことで、より多様な文脈を捉えるための仕組みです。この図を見ることで、Transformerモデル、ひいてはCAGで用いられているLLMが、どのように情報を処理しているのかを理解する助けとなります。

CAGでは、各文書をLLMに入力し、各単語やフレーズに対するキーとバリューの値を計算します。そして、これらの値をKVキャッシュとして保存します。この処理は、知識ベース全体に対して一度だけ行われるため、推論時には、この計算を繰り返す必要がありません。
KVキャッシュの生成は、以下の式で表されます。
C_{KV} = KV-Encode(D) (1)ここで、Dは知識ベースに含まれる文書の集合、KV-Encodeは、文書をKVキャッシュに変換する関数を表します。
推論時の高速な応答生成プロセス
ユーザーからクエリが入力されると、CAGは、事前に計算されたKVキャッシュをロードします。そして、クエリとキャッシュされたコンテキストを基に、LLMが応答を生成します。この際、リアルタイムな文書検索は行われません。
具体的には、以下の式に従って応答が生成されます。
ℛ = M(Q | C_{KV}) (2)ここで、Qはユーザーからのクエリ、CKVは事前に計算されたKVキャッシュ、MはLLM、Rは生成された応答を表します。
このプロセスでは、クエリとKVキャッシュを連結したプロンプトがLLMに入力されます。
𝒫 = Concat(Q, 𝐷)このプロンプトにより、LLMは、クエリと知識ベースの両方を考慮した上で、応答を生成することができます。
キャッシュのリセットによる効率的な運用
CAGでは、推論を繰り返す中で、KVキャッシュが徐々に大きくなっていきます。これは、新しいトークンが生成されるたびに、そのトークンに対応するキーとバリューの値がKVキャッシュに追加されるためです。
KVキャッシュが大きくなりすぎると、メモリ使用量が増加し、推論速度が低下する可能性があります。そこで、CAGでは、定期的にKVキャッシュをリセットすることで、この問題を回避します。
具体的には、以下の式に従って、KVキャッシュがリセットされます。
C_{KV}^{reset} = Truncate(C_{KV}, 𝑡₁, 𝑡₂, …, 𝑡ₖ) (3)ここで、CKVは元のKVキャッシュ、t1, t2, …, tkは、新たに追加されたトークン、Truncateは、指定されたトークンをKVキャッシュから削除する関数、C_{KV}^{reset}はリセット後のKVキャッシュを表します。
このリセット処理により、KVキャッシュのサイズを一定の範囲内に抑えることができ、効率的な運用が可能となります。
CAGとRAGの性能比較:実験結果から見える優位性
SQuADとHotPotQAを用いた評価実験
CAGの有効性を検証するため、論文では、SQuAD 1.0とHotPotQAという2つの代表的な質問応答データセットを用いて、CAGとRAGの性能比較実験が行われました。
SQuAD (Stanford Question Answering Dataset) は、Wikipediaの記事とそれに関連する質問、回答のペアから構成されるデータセットです。SQuADでは、質問に対する回答が、必ず対応するWikipediaの記事中に含まれています。
HotPotQAは、複数の文書にまたがる推論を必要とする、より複雑な質問応答データセットです。HotPotQAでは、質問に答えるために、複数の文書から情報を収集し、それらを統合して推論を行う必要があります。
これらのデータセットを用いて、CAGとRAGの性能が比較されました。具体的には、以下の3つの異なる設定で実験が行われました。
- Small: 比較的少量の文書からなる設定
- Medium: 中程度の量の文書からなる設定
- Large: 大量の文書からなる設定
各設定におけるデータセットの統計情報は、以下の表にまとめられています。
| Source | Size | # Docs | # Tokens | # QA Pairs |
|---|---|---|---|---|
| HotPotQA | Small | 16 | 21k | 1,392 |
| Medium | 32 | 43k | 1,056 | |
| Large | 64 | 85k | 1,344 | |
| SQuAD | Small | 3 | 21k | 500 |
| Medium | 4 | 32k | 500 | |
| Large | 7 | 50k | 500 |
比較実験で用いられたベースライン手法
比較実験では、以下の2つの代表的なRAGの手法がベースラインとして用いられました。
- Sparse Retrieval System (BM25): BM25は、情報検索の分野で広く用いられているアルゴリズムです。BM25は、クエリと文書の類似度を、単語の出現頻度や文書の長さなどを基に計算します。
- Dense Retrieval System (OpenAI Indexes): OpenAI Indexesは、OpenAIが開発した、高精度な文書検索システムです。OpenAI Indexesは、クエリと文書を、高次元のベクトル空間に埋め込み、それらのベクトルの類似度を基に、関連する文書を検索します。
これらのベースライン手法とCAGの性能が、BERTScoreを用いて比較されました。BERTScoreは、生成された応答と正解の応答の類似度を、BERTを用いて計算する指標です。
実験結果が示すCAGの優位性
実験の結果、ほとんどのケースで、CAGはRAGを上回る性能を示しました。特に、知識ベースのサイズが小さい場合 (Small) に、CAGの優位性が顕著に現れました。
以下の表は、各設定における、CAGとRAG (Sparse Retrieval SystemとDense Retrieval System) のBERTScoreを示しています。
| Size | System | Top-k | HotPotQA BERT-Score | SQuAD BERT-Score |
|---|---|---|---|---|
| Small | Sparse RAG | 1 | 0.0673 | 0.7469 |
| 3 | 0.0673 | 0.7999 | ||
| 5 | 0.7549 | 0.8022 | ||
| 10 | 0.7461 | 0.8191 | ||
| Dense RAG | 1 | 0.7079 | 0.6445 | |
| 3 | 0.7509 | 0.7304 | ||
| 5 | 0.7414 | 0.7583 | ||
| 10 | 0.7516 | 0.8035 | ||
| CAG (Ours) | 0.7759 | 0.8265 | ||
| Medium | Sparse RAG | 1 | 0.6652 | 0.7036 |
| 3 | 0.7619 | 0.7471 | ||
| 5 | 0.7616 | 0.7467 | ||
| 10 | 0.7238 | 0.7420 | ||
| Dense RAG | 1 | 0.7503 | 0.6188 | |
| 3 | 0.7464 | 0.6869 | ||
| 5 | 0.7428 | 0.7047 | ||
| 10 | 0.7451 | 0.7350 | ||
| CAG (Ours) | 0.7696 | 0.7512 | ||
| Large | Sparse RAG | 1 | 0.6567 | 0.7135 |
| 3 | 0.7424 | 0.7510 | ||
| 5 | 0.7495 | 0.7543 | ||
| 10 | 0.7358 | 0.7548 | ||
| Dense RAG | 1 | 0.6969 | 0.6057 | |
| 3 | 0.7426 | 0.6908 | ||
| 5 | 0.7300 | 0.7169 | ||
| 10 | 0.7398 | 0.7499 | ||
| CAG (Ours) | 0.7527 | 0.7640 | ||
この結果から、CAGは、特に知識ベースのサイズが小さい場合に、RAGよりも優れた性能を発揮することがわかります。これは、CAGが、知識ベース全体を事前に処理することで、関連する情報をより正確に捉えることができるためと考えられます。
また、CAGは、RAGと比較して、推論速度が大幅に高速であることが実験により示されました。以下の表は、CAGと、リアルタイムにKVキャッシュを計算する方式 (w/o CAG) の推論速度を比較したものです。
| Dataset | Size | System | Generation Time (s) |
|---|---|---|---|
| HotpotQA | Small | CAG | 0.85292 |
| w/o CAG | 9.24734 | ||
| HotpotQA | Medium | CAG | 1.66132 |
| w/o CAG | 28.86142 | ||
| HotpotQA | Large | CAG | 2.32667 |
| w/o CAG | 94.34917 | ||
| SQuAD | Small | CAG | 1.06509 |
| w/o CAG | 10.29533 | ||
| SQuAD | Medium | CAG | 1.73114 |
| w/o CAG | 13.35784 | ||
| SQuAD | Large | CAG | 2.40577 |
| w/o CAG | 31.08638 |
この結果から、CAGは、特に知識ベースのサイズが大きい場合に、推論速度の面で大きな優位性を持つことがわかります。これは、CAGが、事前に計算されたKVキャッシュを利用することで、推論時の計算量を大幅に削減できるためです。
これらの実験結果は、CAGが、RAGに代わる、有望なアプローチであることを示しています。特に、知識ベースのサイズが比較的小さく、高速な応答が求められるアプリケーションにおいて、CAGは大きな効果を発揮すると考えられます。
CAGの将来展望と応用可能性
LLMの進化とCAGの適用範囲拡大
CAGは、LLMのコンテキスト長の拡大と、関連情報を抽出する能力の向上に伴い、その適用範囲をさらに広げていくと予想されます。
近年のLLMの進化は目覚ましく、より長いコンテキストを扱えるモデルが次々と登場しています。例えば、GPT-4は、最大で8,192トークン、Claude 3.5は最大で200,000トークンのコンテキストを扱うことができます。このようなコンテキスト長の拡大は、CAGにとって追い風となります。なぜなら、より多くの知識をKVキャッシュに格納できるようになり、より複雑なタスクにも対応できるようになるからです。
また、LLMは、長いコンテキストから関連する情報を抽出する能力も向上しています。これにより、CAGが扱う知識ベースのサイズが大きくなっても、LLMは、クエリに関連する情報を正確に特定し、応答を生成することができるようになります。
これらの技術的な進歩により、CAGは、これまで適用が難しかった、大規模な知識ベースを扱うタスクにも適用できるようになると期待されます。例えば、企業のナレッジマネジメントシステムや、学術論文の検索システムなど、大量の文書を扱う必要があるアプリケーションにおいて、CAGは大きな効果を発揮する可能性があります。
ハイブリッドアプローチによる性能向上
CAGは、RAGと組み合わせることで、さらなる性能向上が期待できます。例えば、基本的な知識はCAGで扱い、例外的なケースや非常に特殊なクエリに対してのみ、RAGを併用する、といったハイブリッドなアプローチが考えられます。
このようなハイブリッドアプローチは、CAGの高速性と、RAGの柔軟性を兼ね備えたシステムを実現する可能性があります。例えば、よくある質問にはCAGで高速に応答し、稀に発生する複雑な質問には、RAGを用いて詳細な情報を検索して応答する、といった使い分けが考えられます。
ハイブリッドアプローチは、CAGとRAGのそれぞれの長所を活かし、短所を補完することで、より高性能なシステムを実現する可能性を秘めています。今後の研究開発により、ハイブリッドアプローチの有効性がさらに明らかになっていくことが期待されます。
多様なアプリケーションへの展開
CAGは、質問応答システムだけでなく、様々なアプリケーションへの展開が期待されます。例えば、以下のようなアプリケーションが考えられます。
- カスタマーサポート: 顧客からのよくある質問に対して、CAGを用いて高速に応答することで、顧客満足度の向上と、オペレーターの負担軽減を実現できます。
- 研究開発: 論文や特許などの大量の文書から、CAGを用いて関連する情報を効率的に抽出することで、研究開発の効率化が期待できます。
- 教育: CAGを用いて、学生からの質問に対して、関連する教材や参考情報を提示することで、学習効果の向上が期待できます。
これらはほんの一例であり、CAGの応用可能性は、アイデア次第で無限に広がっています。今後、様々な分野で、CAGを活用した新しいアプリケーションが登場することが期待されます。
CAGは、LLMの能力を最大限に引き出し、知識集約型のタスクを効率化する、革新的な技術です。LLMの進化に伴い、CAGの適用範囲はさらに拡大し、我々の生活をより豊かにしてくれることでしょう。