

こんにちは、スクーティー代表のかけやと申します。
弊社は生成AIを強みとするベトナムオフショア開発・ラボ型開発や、生成AIコンサルティングなどのサービスを提供しており、最近はありがたいことに生成AIと連携したシステム開発のご依頼を数多く頂いています。
「最近、AIの進化がすごいけど、文章を作るAIって、ちょっと遅い時があるよね…」とお悩みのあなたへ。実は、そんな悩みを解決するかもしれない、新しい技術が登場したんです!それが「 Mercury 」。まるで魔法のように文章を素早く作り出す、画期的なAIです。この記事を読めば、「Mercuryって何?」「他のAIと何が違うの?」「どうしてそんなに速いの?」といった疑問がスッキリ解消します!
この記事では、そんな未来を担うMercuryについて、どこよりも詳しく、わかりやすく解説します。

Mercuryとは?次世代LLMの幕開け
まずはとにかくMercuryをお試しいただいたほうが凄さを実感できると思います。以下のPLAYGROUNDで、無料で試せますので、ぜひ使ってみてください!筆者は結構衝撃を受けました。
Mercuryの概要:従来のLLMとの違い
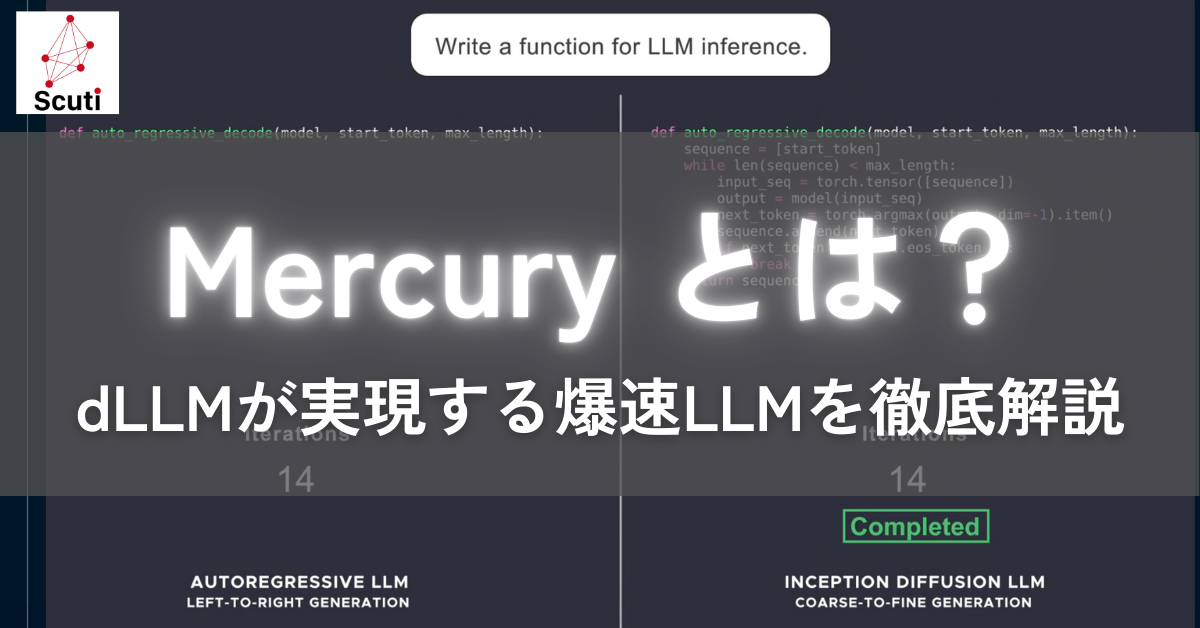
Mercuryは、Inception Labsという会社が発表した、全く新しいタイプの文章を作るAIです。今までの文章を作るAI(LLMと呼びます)は、文章を「今日は」「いい」「天気」「ですね」というように、一つずつ順番に言葉を並べて作っていました。これを「オートリグレッション(AR)」と言います。しかし、Mercuryは「拡散モデル(Diffusion Model)」という、これまでとは全く違う方法を使っています。
拡散モデルは、もともと画像を作るAIでよく使われていた技術です。ノイズだらけのぐちゃぐちゃな画像から、少しずつノイズを取り除いて、きれいな画像を生成します。Mercuryは、この方法を文章に応用することで、今までのAIよりもずっと速く、しかもきれいな文章を作れるようになりました。
Mercuryのコード生成速度は、上記の比較動画で確認できます。Mercuryが他のAIよりも圧倒的に速くコードを生成しているのがわかりますね。
Mercuryの速度:最大10倍高速化の秘密
Mercuryの一番すごいところは、文章を作るスピードです。Inception Labsの発表によると、Mercuryは、他の速いAIと比べても、最大で10倍も速く動くそうです。具体的には、NVIDIA H100という特別なコンピュータの上で、1秒間に1000個以上の言葉(トークン)を作ることができます。これは、今までのAIでは考えられないほどの速さです。
なぜこんなに速いのかというと、拡散モデルの仕組みに秘密があります。従来のAI(ARモデル)は、文章を1つずつ順番に作るため、どうしても時間がかかってしまいます。しかし、拡散モデルは、文章全体を一度に作るため、たくさんの計算を同時に進めることができます(並列処理)。そのため、大幅な高速化が実現できるのです。
Mercuryの基盤技術:拡散モデル
拡散モデルとは?:ノイズから生まれる高品質
拡散モデルは、もともと画像生成AIの分野で注目されていた技術です。仕組みは、大きく分けて次の2つのステップになります。
- 順方向拡散(Forward Diffusion):
- きれいな画像を用意します。
- 少しずつノイズ(砂嵐のようなもの)を加えていきます。
- 最終的には、完全にノイズだらけの状態にします。
- 逆方向拡散(Reverse Diffusion):
- 完全にノイズだらけの状態からスタートします。
- 少しずつノイズを取り除いていきます。
- 元のきれいな画像を復元します。
この「ノイズを取り除く」過程をAIに学習させることで、拡散モデルは、何もないノイズだけの状態から、意味のあるデータ(画像や文章)を作れるようになります(参考論文)。

上記の図は、拡散モデルの仕組みを表しています。左から右へ、ノイズが少しずつ消えていき、最後にはっきりとした絵が出てくるのがわかりますね。
拡散モデルの利点:なぜLLMに有効なのか?
拡散モデルを文章生成AI(LLM)に使うと、主に以下の4つの良いことがあります。
- 高品質な生成:ノイズから徐々に文章を作るため、細かいところまでこだわった、きれいな文章を作れます。
- 多様性:画像、音声、テキストなど、色々な種類のデータを作れます。
- 制御性:生成の過程を細かく調整できるため、「こんな感じの文章を作って」という指示を出しやすいです。
- 優れたフィードバック信号:文章全体を見て、「ここを直して」という指示(フィードバック)を出しやすいため、より高度な修正ができます。
これらの利点は、従来のLLMにはない、拡散モデルならではの強みです。
| 特徴 | 従来のLLM (例:GPT-4o) | 拡散モデル (例:Mercury) |
|---|---|---|
| 生成速度 | 遅い(順番に生成) | 速い(並列処理) |
| 生成品質 | 高い | 非常に高い |
| 多様性 | 比較的高い | 非常に高い |
| 制御性 | 比較的高い | 高い |
| 計算コスト | 高い | 高い(改善中) |

上記の図は、拡散モデルが他の生成モデルと比較して、高品質な画像を生成できることを示しています。具体的には、IMAGENという画像生成モデルの性能を、FIDスコアという指標を用いて比較したものです。FIDスコアは、生成された画像と本物の画像の類似度を表す指標で、値が小さいほど高品質であることを意味します。
図を見ると、IMAGEN(拡散モデル)は、他のモデル(GLIDE, VQ-VAE, GANなど)と比較して、FIDスコアが低く、より高品質な画像を生成できていることがわかります。特に、”w/o classifier guidance”(分類器による誘導なし)と”w/ classifier guidance”(分類器による誘導あり)の両方の場合において、IMAGENが最も低いFIDスコアを達成しています。これは、拡散モデルが、画像の細部まで詳細に捉え、より自然でリアルな画像を生成できることを示しています。
この図から、拡散モデルが画像生成において優れた性能を発揮することがわかります。そして、Mercuryは、この拡散モデルの原理を文章生成に応用しているため、文章生成においても同様に高品質な結果が期待できるのです。
拡散モデルの課題:計算コストの高さ
拡散モデルは、性能が良い反面、計算に時間がかかるという問題がありました。しかし、Mercuryはこの問題を解決し、高速化を実現しました。その具体的な方法は、後の見出しで詳しく説明します。
Mercuryの性能:ベンチマークと実例
コーディングベンチマークでの高い評価
Mercuryは、特にプログラムのコードを作る分野で、とても高い能力を発揮します。Inception Labsによると、Mercury Coderというコードを作るAIは、標準的なコーディングベンチマークにおいて、GPT-4o MiniやClaude 3.5 Haikuといった高速化されたARモデルを凌駕する性能を示しています。具体的には、HumanEvalというテストでは、Mercury CoderはGPT-4o MiniやClaude 3.5 Haikuよりも高い正答率を達成しています。しかも、最大で10倍も高速です。

上記の表は、色々なプログラムのテストで、Mercury Coderがどれくらい良い成績を出したかを示しています。他のAIと比べて、高い点数を取っていることがわかりますね。特に、HumanEvalやMBPPといった、実践的なコーディング能力を測るテストで高い性能を示していることが注目されます。
上記で比較しているモデルは若干バージョンが古いですが、DeepSeek、Gemini、Claudeの直近のモデルに関しては以下の記事で紹介していますので、ぜひご覧ください!

関連記事:Claude 3.7 Sonnet : プログラミング能力最強モデル

関連記事:Gemini 2.0 全モデル完全解説: Flash, Lite, Proを比較

関連記事:DeepSeek v3 の実力と活用法:6710億パラメータのオープンソースMoEモデル
Copilot Arenaでのユーザー評価
Mercury Coderは、Copilot Arenaという、AIのコード生成能力を比べる場所でも、高い評価を得ています。ここでは、色々なAIが作ったコードを、人間が比べて、どれが良いかを評価します。Mercury Coder Miniは、GPT-4o MiniやGemini-1.5-Flashといった速いAIだけでなく、GPT-4oのような、もっと大きなAIよりも良いと評価され、なんと2位になりました。しかも、速さはGPT-4o Miniの約4倍です。
次に示すのは、Inception Labsが公開している、Mercuryと他のAIモデルの速さを比べたグラフです。

棒グラフは、それぞれのAIが1秒間にどれだけの言葉(トークン)を作り出せるかを表しています。棒が高いほど、速く文章を作れるということです。
グラフを見ると、Mercuryは他のAIよりも圧倒的に棒グラフが高く、突出して高速であることがわかりますね。特に、「Mercury Coder Mini」というモデルは、1秒間に1000トークン以上を生成しており、これは他のAIモデルを大きく引き離しています。
また、グラフの下の表は、色々な種類のプログラムのコードを作るテスト(コーディングワークロード)で、それぞれのAIがどれくらいの速さでコードを生成できるかを示しています。 ここでも、Mercury Coder Miniは、他のAIよりもずっと速いことがわかります。
これらのグラフと表から、Mercuryは、他のAIと比べて、圧倒的な速さで文章やコードを作れる、非常に優れたAIであることがわかります。
実際のコード生成例:高速かつ高品質
Mercuryが実際にコードを作っている様子を見てみましょう。以下の動画では、Mercuryが他のLLMと比較して、いかに高速かつ高品質なコードを生成できるかが示されています。
Mercuryの仕組み:詳細な技術解説
dLLM(diffusion large language models)とは?
Mercuryは、dLLM(diffusion large language models)と呼ばれる、新しいタイプのLLMです。dLLMは、「文章全体を一度に作るAI」と考えるとわかりやすいでしょう。拡散モデルの原理を応用して、テキストを生成します。従来のLLMとは異なり、dLLMは、テキスト全体を一度に生成するため、並列処理が可能となり、大幅な高速化を実現できます。この並列処理能力こそが、Mercuryが従来のLLMを凌駕する速度を達成できる鍵となっています。
さらに、拡散モデルは、生成過程でノイズを徐々に除去していくため、生成されるテキストの品質も高いという特徴があります。具体的には、拡散モデルは、まず完全にランダムなノイズからテキストを生成し始めます。そして、複数のステップを経て、徐々にノイズを除去していくことで、最終的に意味のあるテキストを生成します。このプロセスは、あたかも彫刻家が石の塊から彫像を彫り出すように、ノイズの中から意味のある情報を抽出していくようなものです。
この過程で、dLLMは、テキスト全体の構造や文脈を考慮しながら生成を行うため、従来のLLMよりも一貫性のある、自然なテキストを生成することができます。また、生成過程を細かく制御できるため、ユーザーの意図に沿ったテキストを生成することも可能です。例えば、特定のキーワードを含めたり、特定のスタイルで文章を生成したりすることができます。
さらに、拡散モデルは、様々な種類のデータに対応できるため、テキストだけでなく、画像や音声など、他の種類のデータを生成することも可能です。これにより、将来的には、テキストと画像を組み合わせたマルチモーダルなコンテンツの生成も可能になると期待されています。そして、この生成プロセスを制御するために、Algorithm 4 (LLaDAの逆過程(サンプリング)アルゴリズム)が使用されています。Algorithm 4は、ノイズだらけの状態から、徐々に意味のあるテキストを生成していくための手順を示したものです。
連続的な言語空間の利用
dLLMのもう一つの特徴は、連続的な言語空間を利用することです。従来のLLMは、トークンと呼ばれる単語や文字の単位でテキストを処理していました。しかし、dLLMは、トークンを連続的なベクトル空間に埋め込み、その空間上で処理を行います。これにより、より柔軟で自然なテキスト生成が可能になります。言葉の意味を、数字の組み合わせ(ベクトル)で表した世界、と考えると理解しやすいでしょう。
例えば、「猫」と「ネコ」といった表記揺れや、「嬉しい」と「喜ばしい」といった同義語を、より適切に扱うことができます。また、連続的な空間上で処理を行うことで、単語の意味的な関係性をより詳細に捉えることができ、文脈に応じた適切な単語選択が可能になります。Meta社の研究でも、同様の技術の有効性が示唆されています。
連続的な言語空間では、意味が近い単語は近くに配置され、意味が遠い単語は遠くに配置されます。 例えば、「王様」から「男性」のベクトルを引き、「女性」のベクトルを足すと、「女王」のベクトルに近くなる、といった演算が可能になります。
中途段階での推論と修正
dLLMは、生成の途中で推論や修正を行うことができます。従来のLLMは、一度生成を開始すると、最後まで止まることができませんでした。しかし、dLLMは、生成の途中で、生成されたテキストの品質を評価し、必要に応じて修正を加えることができます。これにより、より論理的で一貫性のあるテキストを生成できます。
具体的には、生成されたテキストの一部に矛盾や不自然な点が見つかった場合、その部分にノイズを加え、再度生成し直すことで、より適切なテキストに修正することができます。このプロセスは、人間が文章を推敲する過程に似ており、より高品質なテキスト生成につながります。
さらに、この仕組みを利用して、生成途中のテキストに対して外部からのフィードバックを反映させることも可能です。例えば、ユーザーが生成されたテキストの一部を修正したり、コメントを追加したりすることで、モデルはそれを学習し、よりユーザーの意図に沿ったテキストを生成できるようになります。
この中途段階での推論と修正の機能は、特に長文の生成や、複雑な論理構造を持つ文章の生成において、その真価を発揮すると考えられます。そして、この機能を効率的に行うために、以下のようなアルゴリズムが提案されています。
- Algorithm 1 (EPNDC: Exact Posterior Noised Diffusion Classifier): ノイズが付加されたデータに対する尤度(もっともらしさ)を正確に計算します。生成途中のテキストがどれだけ「もっともらしい」かを評価するために使われます。
- Algorithm 2 (APNDC: Approximated Posterior Noised Diffusion Classifier): Algorithm 1の計算を簡単にしたものです。計算速度を速くしつつ、Algorithm 1と同じような機能を実現します。
- Algorithm 3: 条件付き対数尤度評価アルゴリズム。文章の尤もらしさを評価するために使われます。
- Algorithm 4: LLaDAの逆過程(サンプリング)アルゴリズム。文章を生成する際の中心的なアルゴリズムです。
- Algorithm 5: 低信頼度リマスキング戦略。生成途中で、自信のない部分を特定し、修正を加えるためのアルゴリズムです。
- Algorithm 6: 離散的漸進的クラス選択アルゴリズム。多数の候補の中から、有望な候補を段階的に絞り込むことで、計算量を削減します。
これらのアルゴリズムは、Mercuryが生成途中での推論や修正を行うための基盤技術となっています。
Noised Diffusion Classifiers (NDCs)
Inception Labsは、拡散モデルの分類器としての頑健性を証明するために、Noised Diffusion Classifiers (NDCs)を提案しました。NDCsは、「ノイズに強いAI分類器」と考えるとわかりやすいでしょう。拡散モデルを用いてノイズが付加されたデータを処理し、分類する能力を持ちます。これは、従来の分類器が、ノイズに対して脆弱であるという問題を解決するための重要な技術です(参考論文)。

上記の図は、NDCsの概要を示しています。ノイズまみれの画像から、元の画像を推測し、それが何であるかを分類します。NDCsは、以下のステップで構成されています。
- ELBO (Evidence Lower Bound): データの生成確率の下限を計算します。
- Likelihood: データが与えられた時に、それぞれの種類(クラス)に属する確率を計算します。
- Classifier: 複数の拡散モデルを組み合わせ、それぞれのモデルの意見を総合して(ベイズの定理)分類を行います。
- Smoothed Function: 入力データに小さなノイズを加えることで、分類器の判断が少しの変化で大きく変わらないようにします。
- Certified Radius: 入力データに加えられたノイズの大きさが、ある範囲内であれば、分類結果が変わらないことを保証します。
NDCsの重要な点は、ノイズが付加されたデータに対しても、高い精度で分類を行えることです。これは、拡散モデルが、ノイズを除去する過程で、データの持つ本質的な特徴を抽出できるためです。この特性は、現実世界のデータにノイズが含まれていることが多いことを考えると、非常に重要です。さらに、NDCsは、敵対的攻撃(AIモデルを誤動作させるために意図的に作られた入力データ)に対する耐性も高いことが示されています。これは、NDCsが、データの持つ本質的な特徴に基づいて分類を行うため、表面的なノイズや改変に影響されにくいからです。
Mercuryの今後の展望:AIの未来を変える?
コスト削減と価値創出の加速
Mercuryの高速化は、AIの利用コストを大幅に削減する可能性があります。Inception Labsは、Mercury CoderをNVIDIA H100上で1000トークン/秒以上の速度で動作させることができると発表しています。これは、従来のLLMと比較して、5倍から20倍の高速化に相当します。この高速化は、AIの利用コストを大幅に削減し、より多くの人々がAIの恩恵を受けられるようになることを意味します。
例えば、
- これまでコストの問題でAIの導入をためらっていた企業や研究機関でも、Mercuryを利用することで、AIを活用した新しいサービスや製品の開発が可能になる
- AIの開発サイクルも短縮され、より迅速なイノベーションが期待できる
- 高速化によって、リアルタイムでの応答が必要なアプリケーション(例えば、自動翻訳やチャットボットなど)の性能も向上する
このように、Mercuryの高速化は、AIの普及と発展を加速させる、大きな可能性を秘めていると言えます。具体的には、
- AIによるコンテンツ生成のコストが削減され、より多くの企業や個人が、ブログ記事、広告コピー、ソーシャルメディア投稿などを、手軽に作成できるようになる
- AIによるソフトウェア開発の自動化も加速され、プログラマーの生産性向上に貢献することが期待される
- AIを活用した教育や医療、金融などの分野でも、コスト削減によって、より多くの人々がサービスを利用できるようになる
例:AIによる個別指導や、AIによる診断支援などが、より身近なものになる
このように、Mercuryの高速化は、AIの利用コストを削減し、社会全体に大きな価値をもたらす可能性があります。さらに、AIの高速化は、より複雑なタスクや、より大規模なデータセットを扱うことを可能にします。これにより、これまで解決できなかった問題に対する新たなアプローチが生まれる可能性もあります。
例:気候変動の予測や、新薬の開発など、人類が直面するグローバルな課題の解決に、AIが貢献できる
また、AIの高速化は、人間の創造性を支援するツールとしてのAIの可能性を広げます。
例:デザイナーやアーティストが、AIと協力して、新しいデザインやアート作品を生み出すことができるようになる
このように、Mercuryの高速化は、AIの利用コストを削減するだけでなく、AIの可能性を大きく広げ、私たちの社会に革新的な変化をもたらす可能性を秘めていると言えます。
生涯学習と自己進化するAI
Mercuryのもう一つの可能性は、生涯学習と自己進化です。dLLMは、生成の途中で推論や修正を行うことができるため、ユーザーからのフィードバックや新しい情報に基づいて、リアルタイムにモデルを適応させることができます。これにより、AIは常に最新の情報を学習し、自己進化し続けることができるようになります。
例えば、
- ニュース記事を生成するAIが、新しい出来事やトレンドを自動的に学習し、常に最新の情報に基づいた記事を生成できるようになる
- ユーザーからのフィードバックを反映して、文章のスタイルや表現を改善することも可能
このような生涯学習と自己進化の能力は、AIがより人間らしく、より柔軟に対応できるようになるための重要なステップです。将来的には、AIが自ら学習目標を設定し、自律的に知識を獲得していくようになるかもしれません。Inception Labsの研究は、そのような未来のAIの実現に向けた、大きな一歩となる可能性があります。
ただし、この機能を安全に利用するためには、
- AIが誤った情報や偏った情報を学習しないように、適切な制御メカニズムを設ける
- 信頼できる情報源のみを参照するように制限したり、人間の専門家がAIの学習プロセスを監視したりする
- AIが学習した内容を定期的に評価し、問題がないかを確認する
- AIが自己進化する過程で、人間の価値観や倫理観から逸脱しないように、適切なガイダンスを与える
これらの課題を克服することで、AIは、より安全で信頼性の高いパートナーとして、私たちの社会に貢献できるようになると考えられます。
さらに、生涯学習と自己進化の能力は、AIがより複雑なタスクをこなせるようになるための鍵となります。
例:科学研究や技術開発など、高度な専門知識と創造性が求められる分野において、AIが人間の専門家をサポートしたり、新たな発見を促したりする
また、AIが自ら新しい知識やスキルを獲得することで、人間の能力を拡張し、より豊かな社会を実現できるかもしれません。
例:AIが新しい言語を習得し、異なる文化間のコミュニケーションを円滑にしたり、新しい芸術作品を創造し、人間の感性を刺激したりすることも可能になる
このように、生涯学習と自己進化の能力は、AIの可能性を大きく広げ、私たちの社会に革新的な変化をもたらす可能性を秘めています。
パーソナライズされたAIの実現
dLLMは、連続的な言語空間を利用するため、ユーザーの個性や好みに合わせた、よりパーソナライズされたAIの実現も可能です。
例えば、ユーザーの文章の書き方や、好みの表現などを学習し、そのユーザーに特化した文章を生成することができます。具体的には、ユーザーが過去に書いたメールやレポート、SNSへの投稿などを学習データとして利用することで、そのユーザーの文体や語彙、表現の癖などをモデルに反映させることができます。これにより、AIが生成する文章は、まるでそのユーザー自身が書いたかのような、自然で親しみやすいものになります。
また、ユーザーの興味や関心に基づいて、ニュース記事やブログ記事を要約したり、新しい情報を提案したりすることも可能です。さらに、ユーザーの感情や状態を理解し、それに応じた適切なコミュニケーションを行うこともできるようになるかもしれません。例えば、ユーザーが落ち込んでいる時には、励ましの言葉をかけたり、楽しい話題を提供したりすることができます。
このように、パーソナライズされたAIは、単なる情報提供ツールではなく、ユーザーの良きパートナーとして、日々の生活をサポートしてくれる存在になる可能性があります。Inception Labsの研究は、このような未来のAIの実現に向けた、重要な一歩となるでしょう。
具体的には、
- 個人の趣味や嗜好に合わせたコンテンツの推薦
- 学習スタイルに合わせた教育プログラムの提供
- 健康状態や生活習慣に合わせた健康アドバイス
など、様々な分野でパーソナライズされたAIが活躍することが期待されます。
さらに、企業においては、
- 顧客一人ひとりのニーズに合わせたマーケティングメッセージの作成
- 従業員のスキルや経験に合わせたキャリアパスの提案
など、より効果的なビジネス戦略の立案にも貢献できるでしょう。
ただし、パーソナライズされたAIを実現するためには、プライバシー保護やデータのセキュリティ対策が不可欠です。ユーザーの個人情報や行動履歴を適切に管理し、悪用や漏洩を防ぐための仕組みを構築する必要があります。また、AIがユーザーの情報を過度に利用し、プライバシーを侵害したり、差別的な扱いをしたりすることがないように、倫理的なガイドラインを設けることも重要です。これらの課題を克服し、パーソナライズされたAIを安全かつ効果的に活用することで、私たちの生活はより豊かで、より便利なものになるでしょう。さらに、パーソナライズされたAIは、人間の多様性を尊重し、個性を活かす社会の実現にも貢献できる可能性があります。
- 異なる文化や言語を持つ人々が、互いの文化や言語を理解し、尊重し合うためのツールとして、AIを活用できる
- 障害を持つ人々が、自分の能力やニーズに合わせて情報を取得したり、コミュニケーションを行ったりするための支援ツールとしても、AIは役立つ
このように、パーソナライズされたAIは、単に個人の利便性を向上させるだけでなく、社会全体の多様性と包容性を高めるための重要な役割を果たすことができると考えられます。
Mercuryの潜在的な課題とその対策
計算コストと効率性の両立
拡散モデルは、その性質上、計算コストが高いという課題があります。Mercuryは、この課題を克服するために、様々な工夫を凝らしています。例えば、適応的なノイズ除去スケジュールの採用や、学習可能な停止基準の導入などです。これにより、不要な計算を削減し、効率性を高めています。
- 適応的なノイズ除去スケジュール:生成の初期段階では大まかにノイズを除去し、徐々に細かくノイズを除去していく方法。
- 学習可能な停止基準:生成されたテキストの品質が一定のレベルに達したら、自動的に生成を停止する仕組み。
しかしながら、これらの工夫だけでは、計算コストの問題を完全に解決することはできません。特に、大規模なモデルや、長文の生成においては、依然として高い計算コストが必要となります。
今後の研究では、より詳細なコスト分析が必要となるでしょう。例えば、
- 異なるモデルサイズや、異なるタスクにおける計算コストの比較
- ハードウェアの性能による影響
などを詳細に分析する必要があります。また、計算コストを削減するための新しい技術の開発も重要です。
- 量子化やプルーニングといった技術を応用することで、モデルのサイズを小さくし、計算量を削減できる可能性
- 分散学習や並列処理といった技術を活用することで、複数の計算機を連携させ、大規模なモデルの学習や推論を効率的に行うことも可能
これらの技術的な進歩と、より詳細なコスト分析によって、Mercuryの計算コストの問題は、将来的には克服できると期待されます。さらに、計算効率の高いハードウェアの開発も、Mercuryの普及を後押しするでしょう。
- GPUやTPUといった専用の計算機は、LLMの学習や推論を高速化するために設計されており、Mercuryのような拡散モデルの性能を最大限に引き出すことができる
- 新しいタイプのプロセッサやメモリの開発も、計算コストの削減に貢献する可能性
例:光を利用した計算機や、量子コンピュータなどが実用化されれば、現在のコンピュータでは考えられないほどの高速化が実現できる
このように、ハードウェアとソフトウェアの両面からのアプローチによって、Mercuryの計算コストの問題は、徐々に解決されていくと考えられます。さらに、計算コストの削減は、AIの民主化にもつながります。高価な計算資源を必要としないAIモデルは、より多くの人々や組織が利用できるようになり、AI技術の恩恵を広く社会に普及させることができます。これは、AIの発展を加速させ、より多様な応用分野を開拓することにもつながるでしょう。
評価指標の改善と確立
Mercuryのような新しいタイプのLLMの性能を評価するためには、従来の評価指標だけでは不十分です。例えば、
- グローバルな一貫性(長い文章全体での論理的なつながり)
- 制約への適合性(特定の指示やフォーマットに従う能力)
- 推論の質(複雑な問題を解決する能力)
などを評価する新しい指標が必要になります。従来の評価指標は、主に単語レベルでの正確さや、短い文章での流暢さを評価するものが多く、長い文章全体での一貫性や、複雑な推論能力を評価するには不十分です。
例えば、
- 長い小説や論文を生成する場合、物語の展開に矛盾がないか、論理的な破綻がないかなどを評価する必要がある
- 特定のスタイルやトーンで文章を生成したり、特定のキーワードを含めるように指示したりした場合に、その指示にどれだけ忠実に従えるかを評価することも重要
さらに、複数の情報源から情報を統合し、新しい知識を生成する能力や、複雑な問題を解決するための推論能力も、今後のLLMには求められるようになるでしょう。これらの能力を評価するためには、新しい評価指標の開発が不可欠です。
具体的には、
- 人間の評価者による主観的な評価と、自動的な評価指標を組み合わせることで、より多角的かつ客観的な評価が可能になる
- 評価指標の開発においては、AIの倫理的な側面も考慮する必要がある。例えば、偏見や差別を助長するような表現を生成しないか、誤った情報や有害な情報を提供しないかなどを評価する指標も必要
- 評価指標は、タスクの特性に合わせて調整する必要がある
例:ニュース記事の生成と、小説の生成では、求められる文章の品質が異なります。ニュース記事では、正確性や客観性が重視されますが、小説では、創造性や表現力が重視されます。したがって、それぞれのタスクに適した評価指標を開発し、適用することが重要。
また、評価指標は、常に改善し続ける必要があります。AI技術の進歩に伴い、LLMの能力も向上していくため、従来の評価指標では、LLMの性能を正確に評価できなくなる可能性があります。そのため、常に新しい評価指標を開発し、既存の評価指標を見直す必要があります。このように、評価指標の改善と確立は、LLMの研究開発において、非常に重要な課題であり、今後の研究の進展が期待されます。
具体的には、
- 人間の評価者による評価を効率化するためのツール
- 自動評価指標の精度を向上させるための技術の開発
が求められます。
また、評価指標の妥当性や信頼性を検証するための研究も重要です。さらに、評価指標の開発においては、多様な視点を取り入れることが重要です。例えば、言語学、心理学、社会学などの専門家の知見を活用することで、より包括的で多角的な評価指標を開発することができるでしょう。これらの取り組みを通じて、LLMの性能をより正確に評価し、その発展を促進することが可能になると考えられます。そして、論文中に登場する数式は、これらの評価指標や、拡散モデルの挙動を理解するための、より深い洞察を与えてくれるものですが、今回の記事では、高校生にもわかりやすいように、数式そのものの解説は省略しています。
トークン化からの脱却:連続的な言語空間の探求
Mercuryの可能性を最大限に引き出すためには、トークンという概念から脱却し、連続的な言語空間を直接扱うことが重要です。これにより、より自然で流暢なテキスト生成が可能になり、言語の微妙なニュアンスや文脈をより深く理解できるようになると考えられます。従来のLLMは、テキストをトークンと呼ばれる単語や文字の単位に分割して処理していました。しかし、トークンは離散的なシンボルであり、言語の持つ連続的な性質を捉えきれていませんでした。「言葉の意味を、数字の組み合わせ(ベクトル)で表した世界」を想像してみてください。この世界では、
- 「赤い」と「紅い」は、どちらも同じ色を表す言葉ですが、微妙なニュアンスの違いを、ベクトルの位置の違いとして表現できます。
- 「嬉しい」と「喜ばしい」といった同義語も、ベクトル空間上で近い位置に配置され、意味的な類似性が表現されます。
連続的な言語空間では、単語や文をベクトルとして表現するため、これらの微妙な違いを捉えることができます。また、連続的な空間上で演算を行うことで、単語の意味を合成したり、文の意味を変化させたりすることも可能です。例えば、「赤い」+「花」=「赤い花」といった演算や、「嬉しい」+「悲しい」=「複雑な気持ち」といった演算が可能になります。これにより、より豊かで表現力のあるテキスト生成が可能になると期待されます。
さらに、連続的な言語空間は、
- 異なる言語間の翻訳
- テキストと画像の間の変換
など、マルチモーダルなタスクにも応用できる可能性があります。
例えば、
- 英語の文章をフランス語の文章に翻訳する際に、両方の言語の文章を同じ連続的な空間上に表現することで、よりスムーズな翻訳が可能になる
- 画像の内容を説明する文章を生成したり、文章の内容に合った画像を生成したりすることも、連続的な空間を利用することで、より自然に行えるようになる
Meta社の研究では、この連続的な言語空間を利用することで、多言語間でのゼロショット学習(ある言語で学習したモデルを、別の言語にそのまま適用すること)が可能になることが示唆されています。これは、異なる言語の概念が、連続的な空間上で類似した位置に配置されるためと考えられます。このように、連続的な言語空間の探求は、LLMの性能を向上させるだけでなく、AIの応用範囲を広げる可能性を秘めています。

上記の図は、連続的な言語空間における概念の表現を示しています。言葉と言葉が、意味の近さに応じて、空間上に配置されている様子がわかりますね。例えば、「王様」から「男性」の意味を引いて、「女性」の意味を足すと、「女王」に近くなる、といった関係性を、この空間上で表現できます。
MercuryがもたらすAIの未来
Mercuryは、従来のLLMの常識を覆す、革新的な技術です。その圧倒的な速度と高品質な生成能力は、AIの利用範囲を大きく広げる可能性を秘めています。また、拡散モデルの特性を活かした、生涯学習、自己進化、パーソナライズといった機能は、AIの未来を大きく変えるかもしれません。従来のLLMは、大量のデータから学習することで、高い性能を達成してきましたが、その学習プロセスは静的であり、一度学習が完了すると、新しい情報や状況に適応することができませんでした。
しかし、Mercuryは、生成の途中で推論や修正を行うことができるため、常に最新の情報を取り込み、自己進化し続けることができます。これにより、AIは、より柔軟で、より人間らしい知性を獲得することができるようになるでしょう。例えば、ユーザーとの対話を通じて、ユーザーの好みや意図を学習し、よりパーソナライズされた情報を提供したり、新しい知識やスキルを自律的に獲得したりすることができるようになるかもしれません。また、複数のAIが互いに協力し、より複雑な問題を解決したり、新しいアイデアを生み出したりすることも可能になるでしょう。このようなAIの進化は、社会の様々な分野に大きな影響を与える可能性があります。例えば、教育、医療、ビジネス、エンターテイメントなど、あらゆる分野で、AIが人間のパートナーとして活躍するようになるかもしれません。
もちろん、Mercuryにはまだ課題も残されています。計算コストの高さや、評価指標の確立、トークン化からの脱却など、解決すべき問題は山積しています。しかし、その可能性は計り知れません。今後の研究開発によって、MercuryがAIの新たな地平を切り開くことを期待しましょう。そして、その進化が、私たちの社会をより豊かで、より便利なものにしてくれることを願っています。具体的には、より効率的なアルゴリズムの開発や、ハードウェアの性能向上によって、計算コストの問題を解決し、より多くの人々がMercuryの恩恵を受けられるようにすることが重要です。また、新しい評価指標の開発や、既存の評価指標の改善によって、Mercuryの性能をより正確に評価し、さらなる改善につなげる必要があります。さらに、連続的な言語空間の研究を進め、トークンという概念から脱却することで、より自然で流暢なテキスト生成を実現し、AIの表現力を高めることが求められます。
これらの課題を克服し、Mercuryの潜在能力を最大限に引き出すことで、AIは、私たちの社会に革新的な変化をもたらすでしょう。そして、その変化は、私たちが想像する以上に、大きく、そして速いものになるかもしれません。AIの進化は、私たちの生活や仕事、社会のあり方を根本的に変える可能性を秘めています。Mercuryは、その進化の最前線に立つ、画期的な技術であり、今後の動向から目が離せません。