

こんにちは、スクーティー代表のかけやと申します。
弊社は生成AIを強みとするベトナムオフショア開発・ラボ型開発や、生成AIコンサルティングなどのサービスを提供しており、最近はありがたいことに生成AIと連携したシステム開発のご依頼を数多く頂いています。
Anthropicは、Retrieval-Augmented Generation (RAG) における情報検索の精度を向上させる新しい手法「Contextual Retrieval」を発表しました。
Contextual Retrievalは、従来のキーワードマッチングや意味検索に加えて、ユーザーのクエリやタスクの文脈を深く理解することで、より正確で適切な情報を提供します。特に、プログラミングや技術的な質問など、文脈理解が重要なタスクにおいて効果を発揮します。
この記事では、Contextual Retrievalの概要をご紹介します。
本題に入る前に、生成AIとは何か?ChatGPTとは何か?を確認しておきたい方は、下記の記事を御覧ください。

Contextual Retrievalとは
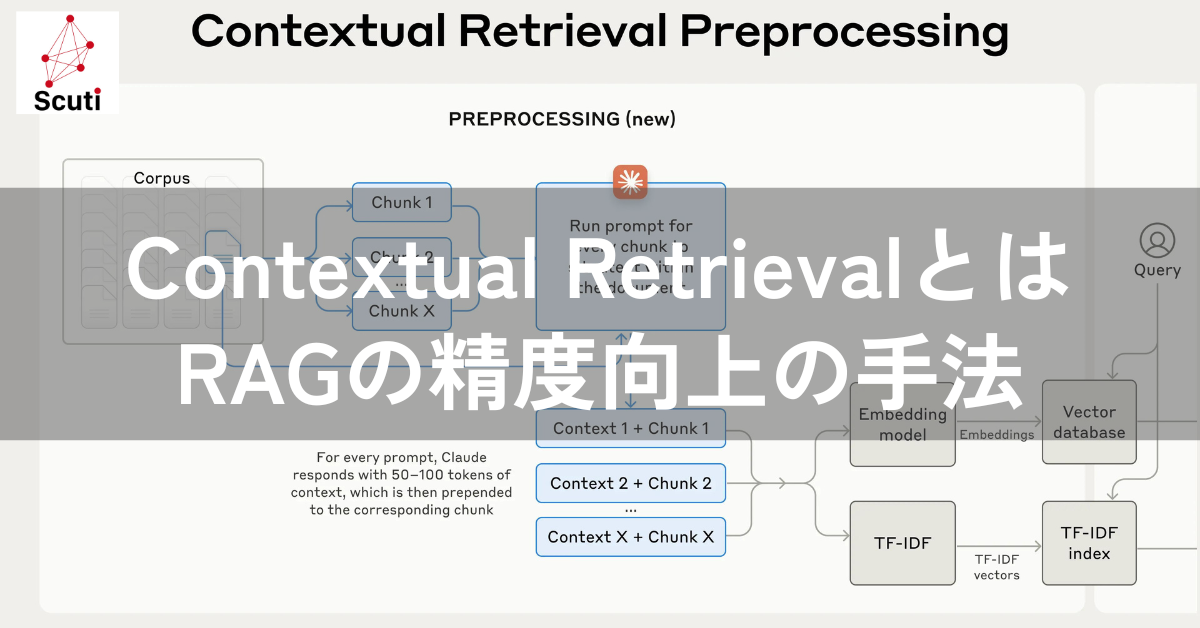
Contextual Retrievalとは、RAGシステムにおいて、知識ベースから情報を取得する際に、取得する情報の断片(チャンク)に文脈情報を付加することで、RAGの検索精度を向上させる手法です。
RAGでは、ドキュメントを小さなチャンクに分割して埋め込みを作成しますが、チャンク単体では十分な文脈情報が不足している場合があり、検索精度が低下する原因となっていました。
Contextual Retrievalは、埋め込みを作成する前に、チャンクに文脈情報を付加することで、この問題に対処します。具体的には、LLM(大規模言語モデル)を使用して、各チャンクの内容を説明する簡潔な文脈情報を生成し、チャンクの先頭に付加します。
Contextual Retrievalの動作メカニズム
Contextual Retrievalは以下の処理プロセスから構成されます。
- チャンクの分割: まず、ドキュメントを意味のある単位でチャンクに分割します。チャンクの分割方法は、固定長の文字数で分割する方法や、文の境界で分割する方法、見出しで分割する方法など、さまざまな方法があります。
- 文脈情報の生成: LLMを用いて、各チャンクに対して、ドキュメント全体の内容を踏まえた文脈情報を生成します。例えば、あるチャンクが「前四半期と比較して、会社の収益は3%増加しました。」という内容だった場合、LLMはドキュメント全体の内容を分析し、「このチャンクは、ACME社の2023年第2四半期の業績に関するSEC提出書類からのものです。前四半期の売上高は… 、営業利益は…でした。」といった、より詳細な文脈情報を生成します。
- チャンクへの文脈情報付加: 生成された文脈情報を、対応するチャンクの先頭に付加します。
- 埋め込みの作成: 文脈情報が付加されたチャンクに対して、埋め込みモデルを用いて埋め込みを作成します。
従来のRAGにおけるチャンク分割とContextual Retrievalを用いたチャンク分割の例
従来のRAGにおけるチャンク分割:
ドキュメント全体を固定長の文字数で分割します。
- チャンク1: “ACME社は、2023年第2四半期の業績を発表しました。売上高は前年同期比10%増の…”
- チャンク2: “…前四半期と比較して、会社の収益は3%増加しました。これは、…”
- チャンク3: “…新製品の販売が好調だったことによるものです。…”
Contextual Retrievalを用いたチャンク分割:
ドキュメント全体を固定長の文字数で分割し、各チャンクに文脈情報を付加します。
- チャンク1: “このチャンクはACME社の2023年第2四半期の業績に関するSEC提出書類からのものです。前四半期の売上高は… 、営業利益は…でした。 ACME社は、2023年第2四半期の業績を発表しました。売上高は前年同期比10%増の…”
- チャンク2: “このチャンクはACME社の2023年第2四半期の業績に関するSEC提出書類からのものです。前四半期の売上高は… 、営業利益は…でした。 前四半期と比較して、会社の収益は3%増加しました。これは、…”
- チャンク3: “このチャンクはACME社の2023年第2四半期の業績に関するSEC提出書類からのものです。前四半期の売上高は… 、営業利益は…でした。 新製品の販売が好調だったことによるものです。…”
このように、Contextual Retrievalを用いることで、各チャンクがドキュメント全体のどの部分を指しているのか、また、そのチャンクの前後関係がより明確になり、検索精度が向上という仕組みです。
従来のRAGとの違い
従来のRAGでは、チャンクの埋め込みはチャンクのテキスト情報のみから作成されます。一方、Contextual Retrievalでは、チャンクのテキスト情報に加えて、ドキュメント全体の文脈情報も埋め込みに反映されます。これにより、検索クエリに対して、より文脈に沿った適切なチャンクが取得できるようになります。
Contextual Retrievalにおける情報検索の仕組み
Contextual Retrievalでは、ユーザーが入力したクエリに対して、関連性の高い情報を効率的に取得するために、以下の手順で情報検索を行います。
- クエリ分析: ユーザーのクエリを解析し、キーワードやフレーズ、検索意図などを抽出します。
- 埋め込みの取得: クエリ分析の結果に基づいて、クエリに対応する埋め込みベクトルを生成します。
- 類似度計算: 生成されたクエリの埋め込みベクトルと、知識ベースに保存されている各チャンクの埋め込みベクトルとの類似度を計算します。
- 候補チャンクの選択: 類似度計算の結果に基づいて、クエリに関連性の高いチャンクを上位から一定数選択します。
- 情報抽出: 選択されたチャンクから、クエリの回答に適した情報を抽出します。
- 応答生成: 抽出された情報に基づいて、ユーザーに提示する応答を生成します。


Contextual EmbeddingsとContextual BM25
Contextual Retrievalでは、文脈情報を利用した情報検索のために、Contextual EmbeddingsとContextual BM25という2つの手法を組み合わせることができます。
- Contextual Embeddings: 文脈情報が付加されたチャンクの埋め込みを、埋め込みモデルを用いて作成します。これにより、チャンクの意味的な類似性を考慮した検索が可能になります。
- Contextual BM25: BM25は、情報検索において広く用いられる手法であり、クエリに含まれるキーワードとドキュメントに含まれるキーワードの一致度を基に、ドキュメントの関連性をスコア付けします。Contextual BM25では、文脈情報が付加されたチャンクに対してBM25を適用することで、キーワードの一致度に加えて文脈情報も考慮した検索が可能になります。
これらの手法を組み合わせることで、意味的な類似性とキーワードの一致度を総合的に判断し、より精度の高い検索結果を得ることができます。
Contextual EmbeddingsとContextual BM25の連携
Contextual EmbeddingsとContextual BM25は、大まかに以下のようなプロセスです。
- クエリに対して、Contextual EmbeddingsとContextual BM25の両方でスコアを計算します。
- それぞれのスコアを、事前に設定した重み付けで統合します。
- 統合されたスコアに基づいて、チャンクのランキングを作成します。
BM25とTF-IDF
BM25は、TF-IDF (Term Frequency-Inverse Document Frequency) を拡張した手法です。TF-IDFは、ドキュメントにおける単語の重要度を、その単語がドキュメントに出現する頻度 (Term Frequency) と、他のドキュメントに出現する頻度の逆数 (Inverse Document Frequency) を用いて計算します。BM25は、TF-IDFに加えて、ドキュメントの長さやクエリの単語数などの要素も考慮することで、より精度の高いスコア付けを実現します。
ベンチマーク結果
Anthropicは、コードベース、フィクション、ArXiv論文、科学論文など、さまざまなデータセットに対してContextual Retrievalのパフォーマンスを評価しました。評価指標として、上位20チャンクに関連するドキュメントが含まれているかどうかを測定するrecall@20を用いました。
その結果、Contextual Retrievalは従来のRAGと比較して、検索精度が向上することが示されました。
- Contextual Embeddings単体では、上位20チャンクの検索失敗率を35%削減 (5.7% → 3.7%)。
- Contextual EmbeddingsとContextual BM25を組み合わせることで、上位20チャンクの検索失敗率を49%削減 (5.7% → 2.9%)。
- さらに、Cohereの再ランク付けモデルを用いた再ランク付けステップを追加することで、上位20チャンクの検索失敗率を67%削減 (5.7% → 1.9%)。


Contextual Retrievalの実装例
プロンプト設計の例
<document>
{{ドキュメント全体の内容}}
</document>
ドキュメント全体の中に配置したいチャンクは次のとおりです。
<chunk>
{{チャンクの内容}}
</chunk>
このチャンクの検索性を向上させるために、このチャンクを文書全体の中に位置づけるための簡潔なコンテキストを記述してください。簡潔な文脈のみを答え、それ以外は答えないでください。
このプロンプトは、ドキュメント全体の内容とチャンクの内容をLLMに提示し、チャンクがドキュメント全体のどの部分を指しているかを簡潔に説明するように指示しています。
例えば、ドキュメント全体が「ある会社の年間業績報告書」で、チャンクが「第2四半期の売上高は前年同期比で10%増加しました」という内容だった場合、LLMは「このチャンクは、会社の年間業績報告書の第2四半期の業績に関する部分を指しています。」といった文脈情報を生成するということです。
Contextual Retrievalの実装例
以下は、PythonとLangChainを用いたContextual Retrievalのかなり単純化した実装例です。詳しくはAnthropicが公開している実装例をご覧ください。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
# OpenAIのAPIキーを設定
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# 埋め込みモデルとLLMを初期化
embeddings = OpenAIEmbeddings()
llm = OpenAI(temperature=0)
# ドキュメントをロードし、チャンクに分割
with open("document.txt", "r") as f:
document = f.read()
chunks = document.split("\n\n") # 空行でチャンクを分割
# 各チャンクに対して文脈情報を生成
contextualized_chunks = []
for chunk in chunks:
context = llm(f"""
<document>
{{ドキュメント全体の内容}}
</document>
ドキュメント全体の中に配置したいチャンクは次のとおりです。
<chunk>
{{チャンクの内容}}
</chunk>
このチャンクの検索性を向上させるために、このチャンクを文書全体の中に位置づけるための簡潔なコンテキストを記述してください。簡潔な文脈のみを答え、それ以外は答えないでください。
""")
contextualized_chunks.append(f"{context} {chunk}")
# 文脈情報が付加されたチャンクをベクトルデータベースに保存
db = Chroma.from_texts(contextualized_chunks, embeddings)
# RetrievalQAチェーンを作成
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
# クエリを入力して回答を取得
query = "会社の第2四半期の業績はどうでしたか?"
answer = qa.run(query)
# 回答を出力
print(answer)コードの説明
- 必要なライブラリをインポートします。
- OpenAIのAPIキーを設定します。
- 埋め込みモデルとLLMを初期化します。
- ドキュメントをロードし、チャンクに分割します。
- 各チャンクに対して文脈情報を生成します。
- 文脈情報が付加されたチャンクをベクトルデータベースに保存します。
- RetrievalQAチェーンを作成します。
- クエリを入力して回答を取得します。
- 回答を出力します。
Contextual Retrievalの応用事例と今後の展望
Contextual Retrievalは、従来のRAGの抱える問題点を解決する有効な手法ですが、いくつかの課題も存在します。
- 計算コスト: LLMを用いて文脈情報を生成するため、従来のRAGと比較して計算コストが高くなる可能性があります。
- レイテンシ: 文脈情報の生成処理が追加されるため、応答速度が遅くなる可能性があります。
- プロンプトエンジニアリング: LLMが生成する文脈情報の質は、プロンプトの設計に大きく依存します。適切な文脈情報を生成するためには、効果的なプロンプトを設計する必要があります。
しかしContextual Retrievalは、まだ比較的新しい技術ですが、すでに多くの企業や研究機関で注目されています。例えば、Googleは、検索エンジンのランキングアルゴリズムにContextual Retrievalの技術を導入することを検討しています。また、Microsoftは、Bing検索エンジンにContextual Retrievalの技術を導入しています。
今後、Contextual Retrievalは、AIチャットボット、質問応答システム、機械翻訳など、さまざまな分野で応用されていくと期待されています。また、LLMの進化に伴い、より高度な文脈理解が可能になることで、Contextual Retrievalの精度もさらに向上していくでしょう。