


こんにちは、スクーティー代表のかけやと申します。
弊社は生成AIを強みとするベトナムオフショア開発・ラボ型開発や、生成AIコンサルティングなどのサービスを提供しており、最近はありがたいことに生成AIと連携したシステム開発のご依頼を数多く頂いています。
米国時間の2024年12月11日、GoogleがGemini 2.0を発表しました。この発表、控えめに言ってやばいです。最新の言語モデルのリリースだけでなく、開発者向けエージェントやGoogle検索との連携など、新機能が一気に発表されました。
OpenAIからは、「12 Days of OpenAI」で12日連続のリリース真っ最中ですが、正直、Googleのほうが大きな話題を提供しているように感じます。GPT-4o超えのGemini-exp-1206しかり、脅威の量子チップ「Willow」しかり。。。
この記事では、Googleの最新AIモデル「Gemini 2.0」の全貌を、開発者向け機能や活用事例、安全性、将来展望まで深掘りし、具体的な活用方法を詳細に解説します。

Gemini 2.0とは
Gemini 2.0の概要
Gemini 2.0は、Googleが開発した最新のマルチモーダルAIモデルです。テキスト、画像、音声、動画など、多様な情報を統合的に処理する能力を持ち、従来のAIモデルを凌駕するパフォーマンスを発揮します。
- Gemini 2.0 Flash: 従来のモデルより高速かつ効率的でありながら、主要なベンチマークで高い性能を達成。
- マルチモーダル対応: テキスト、画像、音声、動画など多様な情報を処理可能。
- ネイティブツール利用: Google検索やコード実行など、外部ツールとの連携が可能。
- Multimodal Live API: リアルタイムでのオーディオ、ビデオストリーミング処理を実現。
- 安全性と倫理: 開発プロセスにおいて、安全性と倫理的な側面に最大限の注意。
- Project Astra: 将来のユニバーサルAIアシスタントのプロトタイプ。
- Project Mariner: ブラウザ上でのタスク自動化を目指す研究プロトタイプ。
- Jules: 開発者を支援するAIコードエージェント。
- ゲーム支援AIエージェント: ゲームプレイをサポートするAIエージェント。
Gemini 2.0が実現する未来
Gemini 2.0の技術的ブレークスルー
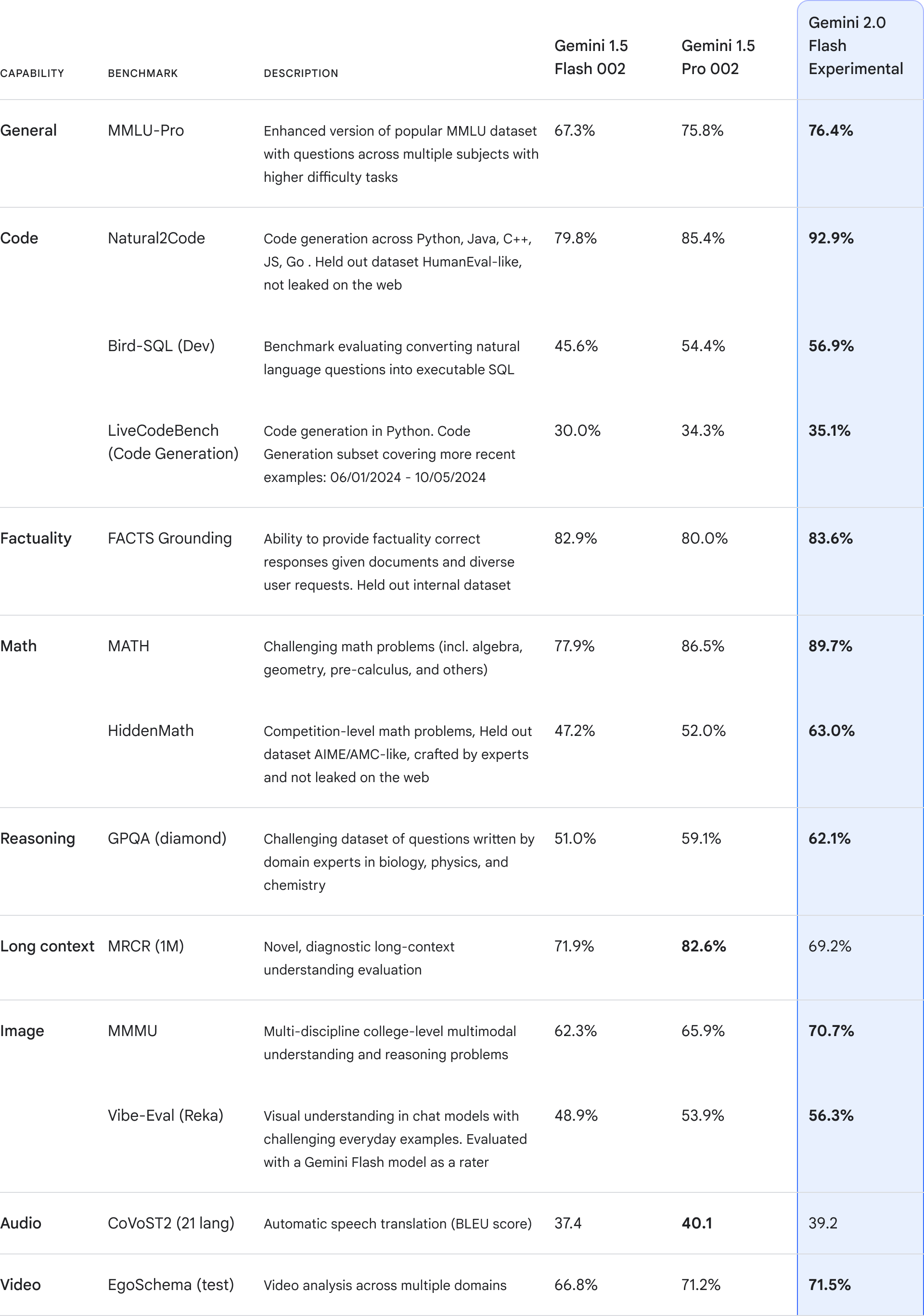
Gemini 2.0は、マルチモーダルAIの新たな地平を切り開く、Googleの最先端技術です。テキスト、画像、音声、動画といった多様な情報を統合的に処理する能力は、従来のAIモデルを大きく凌駕しています。特筆すべきは、Gemini 2.0 Flashのパフォーマンスです。主要なベンチマークでGemini 1.5 Proを上回る性能を達成しつつ、処理速度は2倍という驚異的な効率性を実現しています。これにより、より複雑なタスクを高速に処理することが可能になりました。
さらに、新たなマルチモーダル出力機能を備え、テキスト、画像、音声といった多様な形式での出力に対応します。ここで、Gemini 1.5 ProとGemini 2.0 Flashの性能を比較した表を示します。
| 項目 | Gemini 1.5 Pro | Gemini 2.0 Flash |
|---|---|---|
| 処理速度 | – | Gemini 1.5 Pro の2倍 |
| 対応言語数 | 109言語 | 109以上(増加予定) |
| 主要ベンチマーク性能 | 高い | より高い |
| ツール利用 | 限定的 | ネイティブ対応 |
| API | 従来型 | リアルタイム対応、Multimodal Live API |
| コンテキストウィンドウ | 2M | 1M |
表中の「ツール利用」とは、AIモデルが外部ツール(例:Google検索、コード実行環境など)と連携してタスクを実行する能力を指します。Gemini 1.5 Proでは限定的でしたが、Gemini 2.0 Flashではネイティブに対応し、より高度なタスクの実行が可能になりました。
例えば、レシピの検索を依頼すると、テキストでの手順説明だけでなく、関連する画像や調理の様子を示す動画まで提示できます。これは、単なる情報の提示を超え、より豊かで直感的なユーザーエクスペリエンスの創出に繋がるでしょう。また、ネイティブツールの利用により、Google検索やコード実行など、外部ツールとの連携もスムーズに行えるようになりました。この進化は、AIがより実世界と密接に関わるための重要な一歩と言えるでしょう。
Gemini 2.0 Flashは、その名の通り、高速な処理を得意としています。1.5 Proと比較して、推論スループットが最大3倍に向上しました。これを実現するために、アーキテクチャレベルでの最適化が行われています。具体的には、メモリ使用効率を改善するための新しいアテンションメカニズムの導入や、計算グラフの最適化による不要な計算の削減などが挙げられます。
また、TPUv6 “Trillium”との組み合わせにより、ハードウェアレベルでの最適化も行われています。これらの技術的な工夫により、Gemini 2.0 Flashは、高速でありながら、高い精度を維持することに成功しています。学習データについては、ウェブ上の公開データに加えて、Googleが独自に収集したデータセットも活用されています。
このデータセットには、テキスト、画像、音声、動画など、多様なモダリティのデータが含まれており、それぞれのモダリティ間での関連性も学習されています。また、倫理的な問題やバイアスを排除するために、データのフィルタリングやラベリングにも細心の注意が払われています。学習方法については、トランスフォーマーアーキテクチャをベースとしつつ、マルチモーダルな情報を効率的に処理するための工夫が施されています。
例えば、異なるモダリティの情報を共通の埋め込み空間に射影することで、モダリティ間の関連性を捉えやすくしています。また、自己教師あり学習や敵対的学習などの技術を組み合わせることで、より高度な推論能力を獲得しています。
Gemini 2.0とマルチモーダルLive API
Gemini 2.0の登場で、特に注目すべきは、リアルタイムでオーディオとビデオストリーミングを処理するMultimodal Live APIです。このAPIの導入で、開発者はリアルタイムにカメラやスクリーンから入力されたオーディオとビデオを活用するアプリケーションの開発が可能になりました。ユーザーは自然な会話パターンでAIとやりとりし、アプリケーションは即座に、かつ文脈を理解した上での対応を行うことができます。
Multimodal Live APIで開発できるアプリケーションの例
- リアルタイム翻訳アプリケーション: ユーザーが話した内容をリアルタイムで翻訳し、字幕として表示するアプリケーションを開発できます。このアプリケーションは、例えば、外国語の会議やプレゼンテーションの理解を支援したり、海外旅行でのコミュニケーションを円滑にしたりするのに役立ちます。Gemini 2.0の高度な言語理解能力と、Multimodal Live APIのリアルタイム処理能力を組み合わせることで、高精度かつ低遅延な翻訳を実現できます。
- ビデオ会議システム: ビデオ会議システムに、話者の発言内容の要約、議事録の自動生成、感情分析といった機能を付加することが出来ます。これらの機能は、会議の効率化や、参加者の満足度向上に貢献します。Gemini 2.0のマルチモーダル処理能力を活用することで、音声だけでなく、参加者の表情やジェスチャーなどの非言語情報も分析に加えることができ、より精度の高い会議支援を実現できます。
- オンライン教育プラットフォーム: 生徒の表情や声のトーンを分析し、理解度を把握することで、教師の指導を支援するアプリケーションを開発できます。例えば、生徒が問題を解いている様子をカメラで捉え、表情や視線の動きから、生徒の理解度や困惑の度合いを推定します。この情報を教師にフィードバックすることで、教師は生徒一人ひとりの理解度に合わせた、より効果的な指導を行うことができます。
これらの例は、Multimodal Live APIの可能性のほんの一部です。このAPIを活用することで、開発者は、より人間とAIが自然に対話できるアプリケーションを開発し、ユーザーに新たな体験を提供できます。これは、例えば、ユーザーが部屋の中をカメラで映しながら「この部屋のインテリアに合うアートは?」と尋ねると、AIが即座に部屋のスタイルを分析し、適切なアート作品を提案するといった、よりダイナミックでインタラクティブなアプリケーションの実現を意味します。
また、このAPIを使用すれば、ユーザーの話し言葉の特性を捉え、中断や言い直しを含む自然な会話にも対応することができるようになりました。例えば、ユーザーが話している最中に新しい質問を投げかけても、AIは文脈を維持しながら新しい質問に対応することができます。
Gemini 2.0 Flashによるユーザー体験の向上
Gemini 2.0 Flashは、開発者にとって、よりリッチでインタラクティブなアプリケーションを構築するための強力なツールとなります。例えば、空間認識能力の向上により、画像内の物体の位置関係を正確に把握し、それに基づいた情報提供が可能になります。ビデオで例を見てみましょう。
動画内では、Gemini 2.0による空間認識能力の精度が向上している様子がわかります。例えば、ECサイトで商品を検索する際に、ユーザーが「あの赤いソファーの隣にあるランプ」といった曖昧な指示をしても、AIは正確に商品を特定し、提示できます。
また、ネイティブオーディオ出力機能は、多言語に対応し、8つの高品質な音声から選択可能です。これにより、ユーザーの母国語や好みに合わせた、より自然な対話体験を提供できます。さらに、ユーザーは音声のトーンや抑揚を細かく指定することができ、例えば「明るく元気に話して」といった指示にも対応可能です。
ネイティブイメージ出力機能は、ユーザーの指示に基づいて画像を生成するだけでなく、会話の流れの中で、生成した画像を修正したり、追加の要素を加えたりすることも可能です。これにより、ユーザーはAIと対話をしながら、創造的なプロセスを楽しむことができます。例えば、旅行プランの作成を支援するアプリケーションでは、ユーザーが「ビーチリゾートのイメージを見せて」と指示すると、AIはビーチの画像を生成し、さらに「もっと人が少ない場所がいい」といった要望にも応じて、画像を修正できます。
以下の動画は、Gemini 2.0の新しい機能である「ネイティブオーディオ出力」について紹介しています。
- テキストから音声を生成するだけでなく、その話し方やトーンも細かく制御できること
- 従来のTTS(Text-to-Speech)とは異なり、より人間らしく自然な音声で出力できること
- 一つの音声で多言語を違和感なく話せ、言語間の切り替えもスムーズであること(例:英語で話していたかと思うと、途中からフランス語、韓国語、ヒンディー語、イタリア語、そしてまた英語に戻るといったことが可能)
- ユーザーの状況や文脈に合わせて、声のトーンやスピードを調整できること(例:晴れの日は明るく、雨の日は暗めに、急いでいる時は早口に、など)
- ささやき声や、海賊風など、多様な話し方ができること
この機能は現在、一部のテスターに限定公開されており、来年にはより広範囲に展開される予定です。
Gemini 2.0のネイティブツール活用
Gemini 2.0は、Google検索やコード実行といったツールをネイティブに活用する能力を備えています。この機能により、AIはユーザーの指示に基づき、必要な情報を迅速かつ正確に取得し、タスクを実行できます。例えば、ユーザーが「今日の東京の天気は?」と尋ねると、Gemini 2.0はGoogle検索を自動的に実行し、最新の天気情報を取得して回答します。
また、「Pythonでフィボナッチ数列を計算するコードを書いて」と指示すると、AIはコード実行ツールを活用して、即座にコードを生成し、実行結果を提示できます。さらに、ユーザーはAIに対して、ツールの使用方法を細かく指示することも可能です。例えば、「スポーツに関する質問に答えるときは、必ずGoogle検索を使うこと」といった指示を与えることで、AIの動作をカスタマイズできます。
このネイティブツール利用の機能の中でも、特に強力なのが、Function Callingと呼ばれる機能です。Function Callingを使うと、開発者は、Gemini 2.0に対して、特定のタスクを実行するための独自の関数を定義し、登録することができます。これにより、Gemini 2.0の機能を、開発者のニーズに合わせて拡張することが可能になります。
例えば、社内データベースを検索する関数を登録することで、Gemini 2.0に社内情報を問い合わせることができるようになります。また、特定のAPIにアクセスする関数を登録することで、Gemini 2.0を介して外部サービスと連携することもできます。
Function Callingの活用により、応答速度の向上も期待できます。例えば、従来は複数のステップを踏む必要があった処理を、Function Callingを用いて一つの関数にまとめることで、処理を効率化できます。Googleのテストでは、特定のタスクにおいて、Function Callingを使用した場合、従来の方法と比較して応答速度が50%向上したという結果が出ています。
さらに、Function Callingによって、複雑なタスクをより簡単に実行できるようになります。例えば、複数のツールを組み合わせたタスクを実行する場合、従来はユーザーが各ツールの使い方を理解し、個別に操作する必要がありました。しかし、Function Callingを使えば、複数のツールを組み合わせた処理を一つの関数として定義できるため、ユーザーは複雑な操作を意識することなく、タスクを実行できます。
Gemini 2.0を活用した先進的プロジェクト
Project Astra:未来のユニバーサルAIアシスタント
Project Astraは、Google DeepMindが開発を進める、未来のユニバーサルAIアシスタントのプロトタイプです。このプロジェクトは、Gemini 2.0の高度なマルチモーダル処理能力と記憶能力を活用し、ユーザーの日常生活を包括的にサポートすることを目指しています。
例えば、ユーザーが「あの赤いセーターに合うコーディネートを提案して」と尋ねると、Project Astraはカメラを通してセーターを認識し、色やデザインを分析した上で、最適なコーディネートを提案します。また、過去の会話やユーザーの好みを記憶しているため、「先週話したレストランの予約状況を確認して」といった指示にも対応可能です。
さらに、Project Astraは多言語に対応しており、ユーザーが話す言語を自動的に認識して、適切な言語で応答します。これにより、ユーザーは母国語で自然にAIとコミュニケーションをとることができます。将来的には、スマートフォンやスマートグラスなどのデバイスに搭載され、いつでもどこでもユーザーをサポートする、真のパーソナルアシスタントとなることが期待されています。
Project Mariner:ブラウザでタスクを実行するAIエージェント
Project Marinerは、ユーザーのブラウジング体験を革新する、エージェント型AIの可能性を示す研究プロトタイプです。このプロジェクトでは、Gemini 2.0の高度な推論能力と、Webページ上のテキスト、画像、コードなどの要素を理解する能力を組み合わせることで、ユーザーの指示に基づいてブラウザ上でタスクを実行するAIエージェントを実現しています。
例えば、ユーザーが「最新のスマートフォンを比較して、表形式でまとめて」と指示すると、Project Marinerは自動的に複数のウェブサイトを巡回し、必要な情報を収集して、表形式で提示します。また、「この商品のレビューを要約して」と指示すると、AIは商品ページ上のレビューを分析し、要点をまとめた上で、ユーザーに報告します。
このプロジェクトは、ユーザーがブラウザ上で情報収集やタスク実行を効率化するための、革新的な方法を提供します。将来的には、オンラインショッピング、旅行の計画、リサーチなど、様々なタスクをAIエージェントが代行する未来が訪れるかもしれません。
Jules:開発者を支援するAIコードエージェント
Julesは、ソフトウェア開発の現場に革新をもたらす、AIコードエージェントのプロトタイプです。Gemini 2.0の高度なコード生成能力と、ソフトウェア開発プロセスへの深い理解を組み合わせることで、開発者のコーディング作業を強力に支援します。
例えば、開発者が「ユーザー認証機能を実装して」と指示すると、Julesは必要なコードを自動的に生成し、プロジェクトに統合します。また、「このコードのバグを修正して」と指示すると、AIはコードを分析し、問題点を特定した上で、修正案を提示します。
さらに、JulesはGitHubなどのバージョン管理システムと連携し、コードの変更履歴を追跡したり、プルリクエストを作成したりすることも可能です。このプロジェクトは、開発者がバグ修正や定型的なコーディング作業から解放され、より創造的なタスクに集中できる環境を提供します。
将来的には、AIがソフトウェア開発のあらゆる側面を支援し、開発プロセスを大幅に効率化する未来が訪れるかもしれません。
出典:https://developers.googleblog.com/en/the-next-chapter-of-the-gemini-era-for-developers/
ゲーム支援AIエージェント:仮想世界での新たな体験
Google DeepMindは、Gemini 2.0を活用して、ゲームプレイを支援するAIエージェントの研究も進めています。このエージェントは、ゲームの画面をリアルタイムで分析し、プレイヤーの状況を把握した上で、戦略的なアドバイスやヒントを提供します。
例えば、ユーザーが、リアルタイムストラテジーゲームで「次の攻撃をどこに仕掛けるべきか?」と質問すると、エージェントは、ゲームの状況を分析し、「敵の防御が手薄な地点に集中攻撃するのが効果的です」といった具体的なアドバイスを提示してくれます。
また、このエージェントは、ゲーム内のルールやメカニズムを理解しているため、初心者プレイヤーに対して、ゲームの進め方を丁寧に説明したり、効果的な戦略を提案したりすることも可能です。さらに、このエージェントは、Google検索と連携することで、ゲームに関する最新情報や攻略情報を取得し、プレイヤーに提供することもできます。
この研究は、ゲームプレイの体験をより豊かにし、プレイヤーがより深くゲームの世界に没入できる未来を示唆しています。
Gemini 2.0の責任ある開発と安全性
安全性と倫理への取り組み
Googleは、Gemini 2.0の開発において、安全性と倫理的な側面に最大限の注意を払っています。AIモデルの高度化に伴い、潜在的なリスクを特定し、軽減するための取り組みが不可欠です。
そのため、Googleは、社内の専門家チームによる厳格な安全性評価を実施し、モデルの動作を詳細に分析しています。また、外部の専門家や倫理学者との協力を通じて、多様な視点を取り入れ、より客観的かつ包括的な安全性評価を行っています。
さらに、Googleは、AIの責任ある開発と利用に関する原則を策定し、公開しています。これらの原則に基づき、Gemini 2.0の開発と運用が行われており、AI技術の恩恵を社会全体で享受できるよう、透明性と説明責任を重視しています。
プライバシー保護とユーザーの制御
Googleは、ユーザーのプライバシー保護を最優先事項と位置づけ、Gemini 2.0の開発と運用において、厳格なプライバシー保護対策を実施しています。
例えば、Project AstraのようなAIアシスタントでは、ユーザーが自分のデータを管理し、AIとのやり取りの履歴を削除できる機能を備えています。また、ユーザーがAIに対して、どのような情報を記憶し、どのように利用するかを細かく指示できる仕組みも導入されています。
さらに、Googleは、AIモデルの学習に使用するデータセットの構築において、個人情報の匿名化やデータの最小化などのプライバシー保護技術を適用しています。これらの取り組みにより、ユーザーは安心してGemini 2.0を利用し、AI技術の恩恵を享受することができます。
AIエージェントのリスク評価と対策
AIエージェントの高度化に伴い、潜在的なリスクを特定し、対策を講じることが重要です。Googleは、Gemini 2.0を活用したAIエージェントの開発において、厳格なリスク評価プロセスを実施しています。
例えば、Project Marinerのようなブラウザ操作エージェントでは、ユーザーの意図しない操作や情報漏洩のリスクを評価し、対策を講じています。具体的には、エージェントが実行する操作をユーザーが常に確認し、承認できる仕組みを導入しています。
また、機密情報を含むウェブページへのアクセスを制限したり、ユーザーの認証情報を安全に管理したりする機能も備えています。さらに、Googleは、AIエージェントの動作を監視し、異常な挙動を検知するシステムの開発にも取り組んでいます。
これらの対策により、AIエージェントの安全な運用を確保し、ユーザーが安心して利用できる環境を提供しています。
Gemini 2.0が支えるGoogleの未来戦略
Trillium TPUによるAIインフラの強化
Googleは、Gemini 2.0の性能を最大限に引き出すために、AIインフラの強化にも注力しています。その中核を担うのが、第6世代のTensor Processing Unit(TPU)であるTrilliumです。
Trilliumは、前世代のTPUと比較して、4.7倍のピーク演算性能を実現し、AIモデルの学習と推論を大幅に高速化します。また、エネルギー効率も67%向上しており、大規模なAIモデルの運用コストを削減できます。
さらに、Trilliumは、最大256チップを単一のドメインとして接続できる、高速なチップ間インターコネクトを備えており、最大10万個以上の規模にまで、容易にスケールさせることができます。具体的には、256チップで構成されるTrilliumポッドを単一の単位として、複数のポッドを組み合わせることで、大規模なAIモデルの学習を効率的に行うことが可能になります。
このスケーラビリティにより、Gemini 2.0のような大規模モデルの学習を効率的に行うことができます。Googleは、Trilliumを搭載したAIスーパーコンピュータを構築し、社内のAI研究開発に活用するとともに、Google Cloudを通じて、企業や開発者に提供しています。

AI HypercomputerによるAI開発の加速
Googleは、Trillium TPUを中核とする、AI開発のための包括的なプラットフォームとして、AI Hypercomputerを提供しています。AI Hypercomputerは、ハードウェア、ソフトウェア、アルゴリズムを最適化し、AIモデルの学習、推論、デプロイメントを効率化します。
開発者は、AI Hypercomputerを利用することで、Gemini 2.0のような最先端のAIモデルを容易に活用し、革新的なアプリケーションを迅速に開発できます。また、AI Hypercomputerは、オープンソースのフレームワークであるJAX、PyTorch、TensorFlowをサポートしており、開発者は使い慣れたツールでAIモデルを構築できます。
さらに、Google Cloud上で提供されるため、スケーラビリティや信頼性の高いインフラを利用できます。AI Hypercomputerは、AI開発のあらゆる側面を支援し、イノベーションを加速するための強力なプラットフォームとなっています。
Deep Research:Gemini Advancedの新機能
Deep Researchは、Gemini Advancedのユーザーが利用できる新機能であり、AIを活用した高度なリサーチツールです。ユーザーが質問を入力すると、Deep Researchは、複数のステップからなるリサーチプランを自動的に作成し、ユーザーの承認を得た上で、Web上の情報を深く分析します。
例えば、ユーザーが「自動運転技術の最新動向について調べて」と指示すると、Deep Researchは、関連するウェブサイトや論文を検索し、情報を収集して、要点をまとめたレポートを作成します。このレポートには、元の情報源へのリンクも含まれているため、ユーザーは必要に応じて詳細を確認できます。
また、Deep Researchは、ユーザーの質問に基づいて、継続的にリサーチを行い、情報を更新していきます。この機能により、ユーザーは、複雑なトピックに関するリサーチを効率的に行うことができ、意思決定や問題解決に役立てることができます。Deep Researchは、AIが人間の知的作業を支援する未来を垣間見せる、革新的な機能と言えるでしょう。
出典:https://blog.google/products/gemini/google-gemini-deep-research/
開発者向けGemini APIの提供
Googleは、Gemini 2.0の機能を開発者が容易に利用できるよう、Gemini APIを提供しています。このAPIを通じて、開発者は、Gemini 2.0の高度なマルチモーダル処理能力や、自然言語処理能力を、自身のアプリケーションに組み込むことができます。
例えば、開発者は、Gemini APIを利用して、ユーザーの質問に自然な言語で応答するチャットボットや、画像や動画の内容を理解して、関連する情報を提示するアプリケーションを構築できます。また、Gemini APIは、Google AI StudioやVertex AIなどの開発プラットフォームと統合されており、開発者は使い慣れた環境で、Gemini 2.0を活用したアプリケーションを開発できます。
さらに、Googleは、Gemini APIの利用方法に関するドキュメントやサンプルコードを公開しており、開発者の学習と開発を支援しています。以下に、Gemini APIを使ったサンプルコードを示します。
import google.generativeai as genai
# APIキーの設定
genai.configure(api_key="YOUR_API_KEY")
# モデルの初期化
model = genai.GenerativeModel('gemini-2.0-flash-exp')
# 質問の入力
question = "日本の首都はどこですか?"
# 応答の生成
response = model.generate_content(question)
# 応答の出力
print(response.text)
# 画像とテキストを入力として、応答を生成
image_part = {
"mime_type": "image/jpeg",
"data": open("image.jpg", "rb").read()
}
text_part = {
"text": "この画像に写っているのは何ですか?"
}
response = model.generate_content([image_part, text_part])
print(response.text)
# 複数のツールを組み合わせたFunction Callingの例
def search_google(query):
"""Google検索を実行する関数"""
# Google検索を実行するコードをここに記述
pass
def get_weather(location):
"""指定された場所の天気を取得する関数"""
# 天気情報を取得するコードをここに記述
pass
# 関数の登録
model.register_function(search_google)
model.register_function(get_weather)
# ユーザーからの質問
question = "東京の天気を調べて、その結果に基づいて傘が必要かどうか教えて"
# 応答の生成
response = model.generate_content(question)
print(response.text)
このコードでは、google.generativeaiライブラリを使用して、Gemini APIにアクセスしています。YOUR_API_KEYの部分は、各自のAPIキーに置き換えてください。
最初の例では、generate_contentメソッドを使って、テキストの質問に対する応答を生成しています。2つ目の例では、画像とテキストを組み合わせて入力し、画像に関する質問に対する応答を生成しています。
最後の例では、search_googleとget_weatherという2つの関数を定義し、model.register_functionを使ってモデルに登録しています。これにより、Gemini 2.0は、ユーザーの質問に応じてこれらの関数を自動的に呼び出し、結果を組み合わせて応答を生成することができます。
これらの例からわかるように、Gemini APIを使うことで、開発者は、Gemini 2.0の強力な機能を、自分のアプリケーションに簡単に統合することができます。Gemini APIの提供により、開発者は、Gemini 2.0の革新的な機能を活用し、次世代のAIアプリケーションを創造することができるでしょう。
加えて、開発者は、これらのツールを使用して、より効率的かつ創造的に作業を遂行し、ユーザーに対してよりパーソナライズされた体験を提供できます。例えば、スタートアップ企業がこのAPIを利用して、ユーザーの行動パターンや好みを学習し、それに基づいた商品推薦を行うことで、顧客満足度の向上や売上の増加を実現できます。
さらに、Gemini 2.0の能力を活用して、ユーザーが自然言語で指示を出すだけで、複雑なタスクを自動的に実行するアプリケーションの開発も可能です。
スタートアップ企業によるGemini 2.0の活用事例
多くのスタートアップ企業が、Gemini 2.0を活用して、革新的なサービスやアプリケーションの開発に取り組んでいます。例えば、ある企業は、Gemini 2.0のマルチモーダル処理能力を活用して、ユーザーが描いたラフスケッチを、リアルな画像に変換するサービスを開発しています。
ユーザーが、例えば、「赤い車」と手書きで入力し、簡単な車のスケッチを描くと、Gemini 2.0は、その情報を理解し、リアルな赤い車の画像を生成します。このサービスは、1枚の画像を生成するのに平均で0.5秒しかかからず、ユーザーはストレスなくサービスを利用できます。
また、生成された画像の解像度は1024×1024ピクセルであり、高品質な画像を提供しています。このサービスはリリース後、3ヶ月でユーザー数が10万人を突破し、大きな注目を集めています。
また、別の企業は、Gemini 2.0の自然言語処理能力を活用して、ユーザーの質問に自然な会話形式で応答する、バーチャルアシスタントを開発しています。このアシスタントは、ユーザーの好みや過去のやり取りを記憶し、よりパーソナライズされた情報提供やタスク実行を可能にします。
これらの事例は、Gemini 2.0が、多様な分野で新たな価値を創造する可能性を示しています。
Gemini 2.0による社会課題解決への貢献
Gemini 2.0の高度なAI技術は、社会課題の解決にも貢献することが期待されています。例えば、医療分野では、Gemini 2.0を活用して、医療画像の解析を自動化し、診断の精度向上や効率化を図ることができます。
具体的には、X線写真やCTスキャンなどの画像から、病変を自動的に検出するシステムを開発することが可能です。ある研究では、Gemini 2.0を用いることで、乳がんの検出精度が95%に達し、医師の診断を支援するツールとして有望であることが示されています。
また、教育分野では、生徒一人ひとりの学習進度や理解度に合わせた、個別最適化された学習コンテンツの提供が可能になります。例えば、生徒の解答パターンを分析し、苦手分野を特定して、その分野に特化した問題や解説を提示することができます。
さらに、環境問題への対策として、Gemini 2.0を活用して、衛星画像から森林破壊の状況を監視したり、気候変動の影響を予測したりすることもできます。これらの取り組みに加え、Gemini 2.0は災害救助活動の支援にも役立ちます。
例えば、災害発生時に、被災地の状況をリアルタイムで把握し、救助隊に情報を提供したり、避難経路を案内したりすることが可能です。具体的には、SNS上の投稿や、ドローンで撮影された画像を分析し、被災者の救助や物資の供給を効率化することができます。
さらに、Gemini 2.0は、社会的な格差の是正にも貢献できる可能性があります。例えば、言語の壁を越えたコミュニケーションを支援したり、情報へのアクセスを容易にしたりすることで、より公平な社会の実現に寄与できます。
Gemini 2.0の将来展望と継続的な進化
Googleは、Gemini 2.0を、継続的に進化させることを約束しています。今後、さらなる性能向上や新機能の追加が予定されており、AI技術の可能性を広げていくことが期待されます。
例えば、将来的には、Gemini 2.0が、人間の感情をより深く理解し、共感的な応答を生成できるようになるかもしれません。具体的には、ユーザーの表情や声のトーンから感情を推定し、それに応じた対応をすることが可能になると考えられます。
例えば、ユーザーが悲しんでいるときには、慰めの言葉をかけたり、励ましのメッセージを送ったりすることができるようになるでしょう。また、ユーザーの行動パターンや好みを学習し、より精度の高い予測や提案を行うことも可能になるでしょう。
さらに、Googleは、Gemini 2.0を、オープンなプラットフォームとして発展させることを目指しています。これにより、世界中の開発者や研究者が、Gemini 2.0の技術を活用し、新たなイノベーションを創出することが期待されます。
加えて、Googleは、Gemini 2.0の進化を通じて、人間とAIが協働する未来社会の実現を目指しています。例えば、Gemini 2.0が、人間の創造性を拡張し、新たな芸術作品の創造を支援したり、科学的な発見を加速させたりする可能性があります。
具体的には、アーティストがGemini 2.0と対話しながら、新しいアイデアを得たり、作品の制作を効率化したりすることができるようになるでしょう。また、研究者が、Gemini 2.0を活用して、膨大なデータから新たな知見を発見したり、複雑なシミュレーションを実行したりすることで、研究のスピードを加速させることが期待されます。これらの技術の進化により、Gemini 2.0は、私たちの生活をより豊かに、便利に、そして創造的なものに変えていく可能性を秘めています。
Gemini 2.0が切り拓くAIの未来
Gemini 2.0は、AI技術の新たな時代の幕開けを告げる、革新的なモデルです。その高度なマルチモーダル処理能力、自然言語処理能力、そしてツール活用の能力は、人間とAIの協働を新たなレベルに引き上げます。Gemini 2.0は、私たちの働き方、学び方、そして生活のあらゆる側面を変革する可能性を秘めています。
Googleは、Gemini 2.0を通じて、AI技術の恩恵を社会全体で享受できるよう、責任ある開発と利用を推進しています。今後も、Gemini 2.0の進化から目が離せません。そして、この技術が、私たちの未来をどのように形作っていくのか、大いに期待されます。
さらに、Gemini 2.0は、人間とAIが共存し、互いの能力を高め合う社会の実現に向けた、重要な一歩となるでしょう。例えば、Gemini 2.0は、人間の創造性を拡張し、新たな芸術作品の創造を支援したり、科学的な発見を加速させたりする可能性があります。
また、Gemini 2.0は、人間の意思決定を支援し、より良い選択を行うための情報を提供したり、複雑な問題解決をサポートしたりすることもできるでしょう。具体的には、ビジネスシーンにおいて、Gemini 2.0が、市場の動向を分析し、最適な経営戦略を提案したり、リスクを予測して回避策を提示したりすることが考えられます。
また、個人の生活においても、Gemini 2.0が、健康状態をモニタリングし、最適な健康管理のアドバイスを提供したり、日々のスケジュールを管理して、効率的な時間の使い方を提案したりすることもできるでしょう。Gemini 2.0は、単なるツールではなく、私たちのパートナーとして、より豊かで充実した未来を創造していくための力強い存在となる可能性を秘めています。
具体的には、以下のような未来像が考えられます。
- 教育: 生徒一人ひとりの学習スタイルや理解度に合わせた、個別最適化された学習支援。教師の負担を軽減し、より質の高い教育を実現する。
- 医療: 医療画像診断の精度向上、新薬開発の加速、個別化医療の実現など、医療の質と効率を飛躍的に向上させる。
- 製造業: ロボットと人間の協働による生産性向上、サプライチェーンの最適化、製品開発の効率化など、製造業のあらゆるプロセスを革新する。
- 交通: 自動運転技術の発展、交通渋滞の緩和、交通事故の削減など、より安全で効率的な交通システムの実現。
- エンターテイメント: ユーザーの好みに合わせたコンテンツの自動生成、インタラクティブなゲーム体験の提供など、エンターテイメントのあり方を根本的に変える。
これらはあくまで一例であり、Gemini 2.0の可能性は無限大です。今後、Gemini 2.0がどのように社会に浸透し、どのような未来を創造していくのか、期待は高まるばかりです。

