

こんにちは、スクーティー代表のかけやと申します。
弊社は生成AIを強みとするベトナムオフショア開発・ラボ型開発や、生成AIコンサルティングなどのサービスを提供しており、最近はありがたいことに生成AIと連携したシステム開発のご依頼を数多く頂いています。
SELF-ROUTEという手法が注目されています。RAGの精度を上げる有効な手法のようです。
簡単に言うとRAGとLC(Long-Context:要は、情報源となるテキストをプロンプトにそのまま突っ込むやりかた)のいいところ取りです。この方法で、LCよりもコストを下げつつ、LCとほぼ同等の精度を出せるとのことです。
SELF-ROUTEは仕組みとしてはシンプルなので、Difyのワークフローで再現し、出力を検証してみました!

SELF-ROUTEとは?

SELF-ROUTEは、クエリごとにRetrieval-Augmented Generation(RAG)と長文コンテキスト対応のLLM(LC)のどちらを使用すべきかを、モデル自体の自己フィードバックによって判断する手法です。
RAGは比較的短いコンテキストで優れたパフォーマンスを発揮し、コストが低いという特徴があります。一方で、LCは長文のコンテキスト処理において高い精度を持つものの、計算コストが大幅に増加します。
この2つの手法のバランスを取るために、SELF-ROUTEはまずRAGを使用し、その結果がクエリに対して「回答可能」と判断された場合、RAGの結果を採用します。もし「回答不可能」と判断された場合、LCを使用して再度処理を行います。
つまり、RAGとROUTEのいいところどりです。
この手法は、特に長文のデータセットや複数の質問を含むタスクにおいて有効です。例えば、Gemini-1.5 Proモデルでは、SELF-ROUTEを使用することで65%の計算コストが削減されました。これは、通常であればLCで処理される大部分のクエリを、RAGが低コストで処理できるためです。GPT-4oでも同様に、SELF-ROUTEによって39%のコスト削減が達成されました。
さらに、SELF-ROUTEはトークン数の削減にも寄与します。例えば、RAGはクエリごとに300トークン前後の入力データしか使用しないため、LCの10,000〜100,000トークンと比較して大幅に効率的です。実際に、SELF-ROUTEを用いた場合、全体のクエリの82%はRAGのみで処理され、LCが必要なケースは限られています。この結果、RAGのコスト効率を最大限に活用しつつ、精度の高いLCの利点も享受することができます。
参考論文:Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
DifyでSELF-ROUTEを再現する
Difyを使えばプログラムを書かずに簡単にRAGを作成できるので、DifyでSELF-ROUTEっぽいものを再現し、動作を見てみようと思います。Difyでの設定に関しては、こちらの動画を参考にさせていただきました。
Difyについて
Difyについては以下の記事をご覧ください!
- Difyってなに?という方:DifyでSEO記事作成を試してみる
- DifyでRAGを構築する方法:DifyでRAGを爆速で構築する
Difyの環境構築方法やバージョンアップ方法は本家のレポジトリを参照することをおすすめします。特にバージョンアップ方法はバージョンごとに微妙に方法が変わってきているため、最新版を確認する必要があります。
本記事の検証は、MacOSのローカルPC上に、Dify v0.7.3で検証しましたが、特にこのバージョンでないと使用できない機能を使用しているわけではありません。
SELF-ROUTEを検証するワークフローを作成する
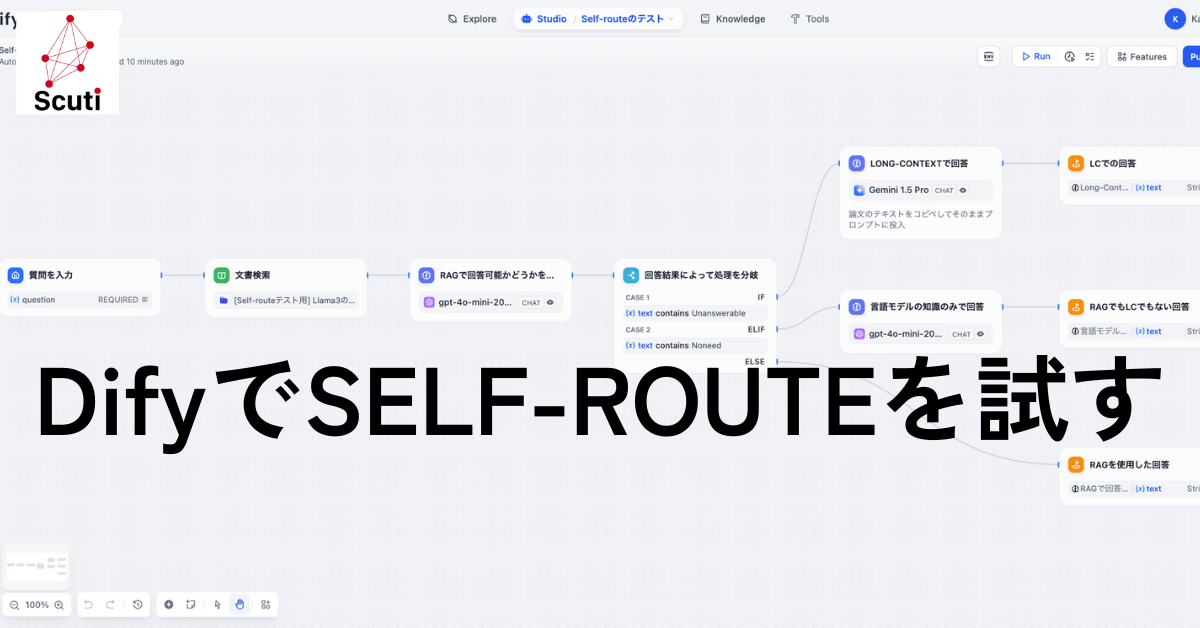
今回Dify上に作成したワークフローは以下のようなものです。ざっくり言うと、ユーザーに何か質問をしてもらい、あらかじめKnowledgeとして登録しておいたPDF文書を参照して回答できるか、文書とは無関係に回答できるか、上記のいずれでもないか、で処理を分岐して回答を出力するというものです。
ポイントだけ以下に詳細を記載します。

Step.1 質問を入力
ユーザーに質問を入力してもらうテキストエリアを用意するだけです。
Step.2 文書を参照
ワークフローには「文書検索」と書いてしまいましたが、まだ「検索」はしていないので、「参照」が正しいと思います。
DifyのKnowledge機能で、あらかじめ検索対象とするPDFファイルを登録しておき、その要約のようなものを出力するブロックです。Knowledgeの登録方法については、上記過去記事の「DifyでRAGを爆速で構築する」をご覧ください。
今回検索対象とするドキュメントとしては、Meta社が公開しているLlama3の論文にしてみました。参考文献のページまで含めると全93ページで全て英語で書かれているので、これを読むのはなかなか骨が折れます。
Step.3 RAGで回答できるかを判別

Step.1で入力された質問に、Step.2で出力したKnowledgeの出力から回答できるかをLLMに判別させるというStepです。このStepでは、LLMはGPT-4o miniの最新バージョンを使用しました(トークン費用節約!)。
このStepがSELF-ROUTEの肝で、かつ、最も調整を必要としました。理由は後述しますが、ここの判別が正しくないと、SELF-ROUTEの期待する動作にならないためです。
与えているプロンプトはキャプチャにある通りですが、以下を判別させています。
- Knowledgeの情報とは無関係に回答可能
- Knowledgeの情報で回答可能
- Knowledgeの情報で回答不可能
1だったら、Step.1で与えられた質問を別のLLM(後述)に与えて回答を生成します。
2だったら、このStepで回答を生成します。
3だったら、次の処理(後述)に移ります。
試行錯誤しながら工夫したのが、上記3つの判断を1→2→3の順番で判断するように指示を与えている点です。この優先順位を指定しないと、私が試した限りでは3のパターンに行きがちでトークン消費量が増えそうだったため、3の優先度を明示的に一番下にしました。
Step.4 回答結果に応じて処理分岐
Step.3の回答結果に応じて次の処理を決める分岐をしています。

Step.5-1 RAGで回答できないのでLCで回答

Step.3の処理で「Knowledgeの情報で回答不可能」と判別された場合に実行される処理です。RAG(Knowledge)の情報では足りないので、LCで回答するということです。
プロンプトは上記のスクリーンショットに写りきっていませんが、Knowledgeとして登録したLlama3の論文のPDFのテキストを全てコピペして、「このテキストから回答して」と指示しています。
全93ページある論文なので、スクリーンショットに少しだけ写っていますが、入力されたトークン数が26万トークン笑 これを毎回実行していたらどんどんトークン費用が膨らんでいくこと間違いないでしょう!
また、大量のトークンを入力するため、このStepではLLMとしてGemini 1.5 Proを選択しています。Google AI Studioを使用すればこのモデルは無料で200万トークンの入力をできますが、APIの場合は有料プランでないとその恩恵を受けられませんでした。
Step.5-2 文書とは無関係な質問に回答する

Step.3の処理で「Knowledgeの情報とは無関係に回答可能」と判別された場合に実行される処理です。
このStepはいたってシンプルで、Step.1で入力された質問に対する回答をLLMに生成してもらっているだけです。ここでもLLMはGPT-4o miniを使用しています。
Step.5-3 RAGを使用して回答
Step.3で「Knowledgeの情報で回答可能」と判別された場合は、Step.3で回答を生成しているため、それをそのまま出力しています。
ここまで設定をさらっとご紹介しました。Difyはプログラムを書かず(書くこともできますが)AIアプリを作れるのが非常に大きな魅力ですが、Difyの仕様や生成AIについてある程度理解していないと実用的なものを構築できないというのも正直なところです。
もしDifyの構築や設定等まるっと任せてしまいたいというご要望ございましたら、ぜひお気軽にご連絡ください!
SELF-ROUTEの出力を検証する
「Knowledgeの情報とは無関係に回答可能」の場合

Meta社が公開する言語モデルのLlama3とは全く無関係な「徳川3代目将軍」を質問してみました。徳川家光と回答されています。

TRACINGタブを見るとどのStepが実行されたかを確認できますが、「言語モデルの知識のみで回答」が生成されているのがわかります。
「Knowledgeの情報で回答可能」の場合

RAGで回答するパターンです。
論文のイントロに記載されているような概要に関する質問であればRAGで回答するだろうという予想のもと、「Llama3とはどの様な言語モデルですか?」という質問をしてみました。
いい感じで短くまとめた回答が出力されています。

TRACINGを見ると、「RAGを使用した回答」が生成されているのがわかります。
「Knowledgeの情報で回答不可能」の場合

これはLCで回答するパターンです。
Step.3に記載した通り、このパターンとして判別される優先度を一番下げているため、どんな質問をしてもRAGで回答され、このパターンにいれるのがなかなか大変でした。
できるだけあとのほうに記載されていて、かつ、詳細を聞くような質問だとLCでの回答になるだろうと予想し、「Llama3で実装されているマルチモーダル機能の5段階の学習方法について教えて」と質問しました。
するとかなり詳細な回答が得られ、論文の該当部の内容と一致するものが回答されました(上記2つ目のスクリーンショットの、OUTPUTの部分がワークフローの出力ですが、全ての出力は写っていません)。
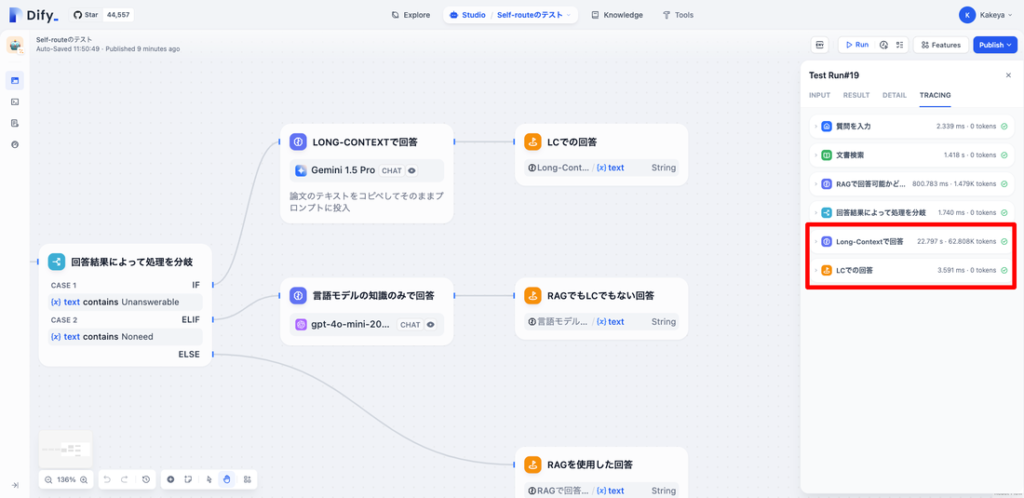
TRACINGを見ると「LCで回答」されていることがわかります。
SELF-ROUTEって結局どうなの?
Difyで簡易的にではありますが、SELF-ROUTEの動作を検証した結果、あくまで私の意見ですが、SELF-ROUTEはあまり実用的ではないと思います。
「実用的」な状態というのは、企業内で大量に文書という形で作成された知見をよりスムーズに共有するためにRAGの仕組みを導入し、その検索精度を向上するために採用できる手段ということです。
今回は93ページのPDFファイルとはいえ1ファイルしか使用しませんでした。上記のような運用を想定するのであれば、対象ファイルは数千、数万にはなるはずで、LCで回答を生成する場合のその全ての文書のテキストを全てプロンプトに入力するのは非現実的です。
やるとすると、Knowledgeを参照するStep.3で、参照元の該当ファイル、あるいは該当ページを絞り込んでおくための前処理を入れておき、LCで回答する場合は、そこに記載されているテキスト「のみ」をプロンプトに入力する方法でしょうか?
いずれにせよ、以下の条件を結構厳しく満たさないことには、SELF-ROUTEを組み込むのは実用的ではないと考えました。
- RAGで回答するのかLCで回答するのかの判別を適切に行えること。「とりあえずLCで回答しておけばいい」という判断をしてしまうようなロジックだと、精度は上がるがコストが大変なことになる。
- LCで回答する場合の入力トークンを限りなく最小化する。