


こんにちは、スクーティー代表のかけやと申します。
弊社は生成AIを強みとするベトナムオフショア開発・ラボ型開発や、生成AIコンサルティングなどのサービスを提供しており、最近はありがたいことに生成AIと連携したシステム開発のご依頼を数多く頂いています。
Difyを活用した調査の自動化に興味をお持ちの方々にとって、効率的な情報収集とレポート生成は大きな課題となります。特に、プライベート環境でのAIアシスタントのデプロイや、独自のインフラストラクチャ上にAIアプリケーションを構築する方法を知りたいというニーズが高まっています。DifyとDeepSeekを組み合わせることで、これらの課題を解決し、調査プロセスを大幅に効率化することが可能です。
この記事では、DifyとDeepSeekを使用してプライベートAIアシスタントをデプロイし、ローカル環境で安全かつ効率的に調査自動化を実現する方法をご紹介します。

DifyとDeepSeekをプライベートに使用する理由

まず、DifyでSEO記事作成を試してみるについて知りたいという方は、ぜひこちらの記事を先にご覧ください。
関連記事:DifyでSEO記事作成を試してみる
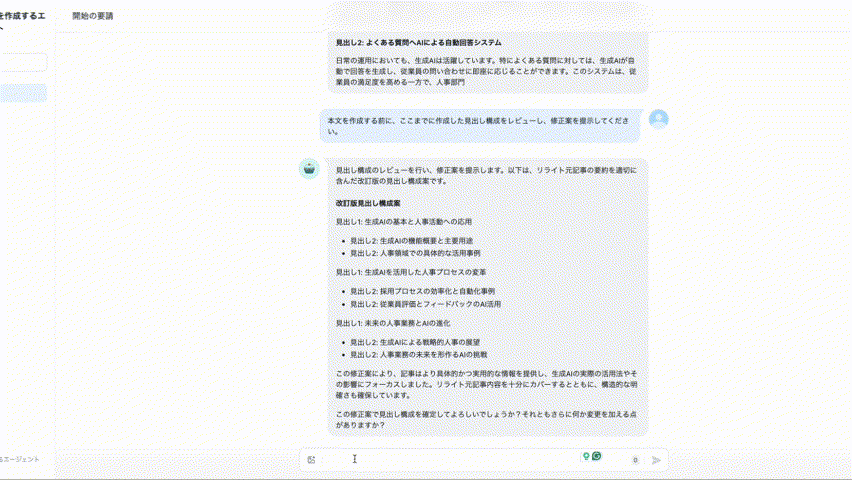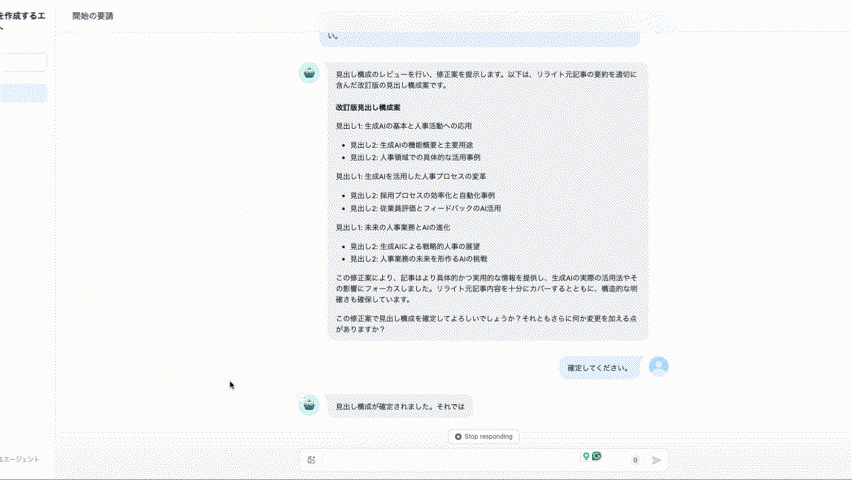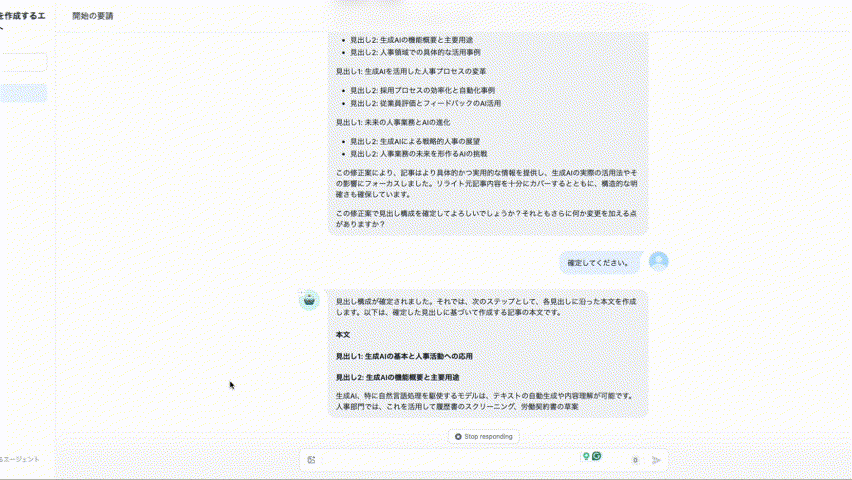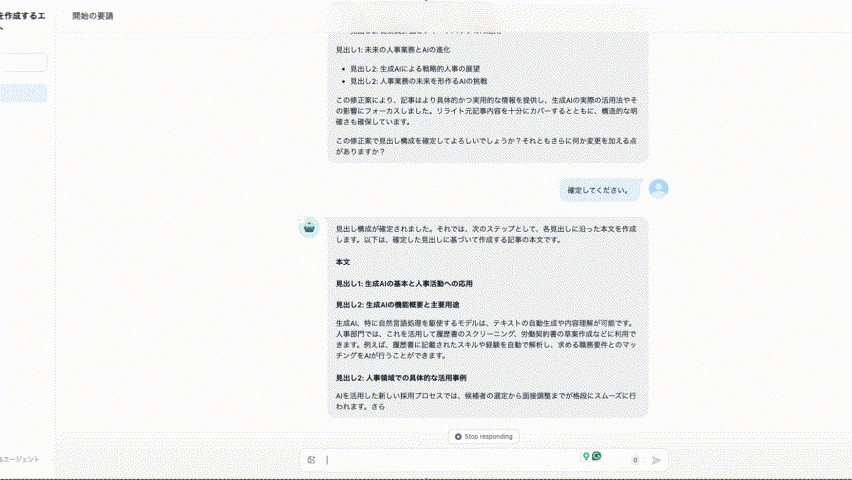
次に、DifyでRAGを爆速で構築するについて知りたいという方は、ぜひこちらの記事を先にご覧ください。
関連記事:DifyでRAGを爆速で構築する
次に、Difyのワークフローを使って今度こそSEO記事を作成するについて知りたいという方は、ぜひこちらの記事を先にご覧ください。
関連記事:Difyのワークフローを使って今度こそSEO記事を作成する
1000以上のAIモデルへのアクセス
Difyは、モデルに依存しないプラットフォームとして設計されており、多様な大規模言語モデル(LLM)の推論機能を活用することができます。これによりユーザーは、DeepSeekをはじめとする複数のAIモデルへの柔軟なアクセスが可能となり、業務や調査に応じた最適なモデルの選択ができます。具体的な利用例では、各種サードパーティのMaaSプラットフォームの中から、自分のニーズに最も沿ったものを簡単に切り替えることができるという点が大きな強みです。
さらに、このプラットフォームはオープンソースとして提供されているため、各種カスタマイズが可能であり、調査や情報収集の自動化に欠かせない多様な機能を統合することができます。このような環境で運用することにより、従来の単一モデルに依存するシステムに比べ、柔軟性と拡張性が大幅に向上するほか、最新のモデル更新や追加が迅速に反映されるメリットも享受できます。
また、Difyのサポート体制やコミュニティの活発さは、システム運用上のトラブルシューティングや新しい機能の追加の際に非常に重要となります。ユーザーは常に最新の情報を得ながら最適なAIツールの環境を整えることができ、結果として業務効率の向上が期待されます。こうした幅広い機能とサポート体制により、1000以上のAIモデルへのアクセスは、専門性の高いプロフェッショナルにとっても大きな魅力となっています。
Difyが多彩なAIモデルに対応し、業務の選択肢を広げる一方、実際に導入するには「自社環境にどう組み込むか」「既存システムとの連携はどうするか」など多くの不安があるものです。
私たちのDify導入支援サービスなら、環境構築からカスタマイズ、運用体制の構築まで、一括でサポートいたします。技術面も運用面も丸ごとお任せください。「これ、もう任せたいかも…」と感じた方は、ぜひ無料相談をご利用ください!
最高のパフォーマンス
DifyとDeepSeekの組み合わせにより、複雑なインタラクションもスムーズに処理できる商用グレードのAIエクスペリエンスを提供します。システム全体で厳選された高性能なAIモデルを利用することができ、調査自動化や多段階のデータ処理においても、処理速度が飛躍的に向上します。例えば、AIアシスタントが多様な入力データに基づいて即座に適切な応答を生成するため、ユーザーは問い合わせに迅速に対応できるようになり、会話の連続性やデータの連携にも影響を及ぼします。
また、理想的な運用環境(例:8コアプロセッサおよび32 GiB以上のメモリ搭載)では、実際の応答速度が200~300ミリ秒以内に抑えられるなど、定量的なメリットも確認されています。さらに、Difyのローコード開発環境はプログラミング初心者でも直感的に操作できる設計となっており、開発者がコーディングに多大な時間を費やすことなく、アプリケーションの迅速な立ち上げを可能にします。これにより、現場の要求に対して即戦力となるAIツールの開発が実現し、業務プロセスの最適化に貢献します。
さらに、商用グレードのパフォーマンスを提供するための最適化も随時行われ、システム全体が常に高い安定性と信頼性を維持しています。実際に運用する際のレスポンス速度は、複数のユーザーからの同時リクエストにも十分耐えられるよう設計されており、ビジネス用途のミッションクリティカルなプロジェクトにも適用可能なシステムとなっています。

隔離された環境
Difyは完全にオフラインで動作するため、外部へのデータ漏洩リスクを排除し、安心してAIアシスタントを利用することが可能です。オフライン環境では、すべての処理がローカルで行われるため、ネットワークを介した不正アクセスや情報流出のリスクが大幅に軽減されます。特に、企業の機密情報や内部調査データを扱う場合、データが外部サーバーに流出することなく安全に管理できる点は非常に大きなメリットです。このような環境は、情報セキュリティの厳しい業界においても高く評価される要素となります。
さらに、オフラインでの運用により、システムのパフォーマンスが向上するだけでなく、外部のサイバー攻撃の影響を受けにくい堅牢な基盤が実現されます。また、オフライン環境での制御は、ユーザー側が常に最新のセキュリティポリシーを維持する上で重要な役割を果たしており、システム自体の更新や改修も外部からの干渉なく行うことができます。こうした隔離された環境の構築は、業界標準のセキュリティ要求やコンプライアンスに完全に準拠するための不可欠な要件であり、結果として信頼性の高いAIアシスタントの提供につながります。さらに、システム障害時の迅速な復旧も見込めるため、ユーザーは常に安全で安定した環境でのシステム運用を実現できます。
完全なデータ制御
Difyを利用することで、ユーザーは全データの完全な制御を実現することができます。データはすべてローカル環境に保存管理され、外部クラウドに依存しないため、企業のセキュリティポリシーや業界規制に厳格に準拠することが可能です。これにより、情報漏洩のリスクを最小限に抑えるのみならず、システム全体の柔軟なカスタマイズが実現され、各種業務に最適なセキュリティ対策が施されます。Difyによる完全なデータ制御は、外部からの不正アクセスが困難な環境を構築できる点で特筆すべきです。全てのデータ管理プロセスがユーザー自身の手によって行われるため、リアルタイムでのデータ監視や必要に応じたアクセス権の管理が容易に実施可能です。
さらに、コンプライアンス遵守のための各種レポート作成やログの管理も、システム内で完結するため、外部へのデータ送信を伴わない安全なデータ運用が保証されます。これらの機能は、大規模な調査業務や極秘情報を扱うプロジェクトにおいて、安心して利用できる基盤を提供し、企業全体のセキュリティレベルを向上させる効果があります。長期的な視点で見ても、Difyのプラットフォームによるデータ制御は、運用コストの削減やリスクヘッジの観点からも非常に有効であり、利用者に多大なメリットをもたらす仕組みとなっています。
メリット:
・1000以上のAIモデルへの柔軟なアクセス
・高速で信頼性の高いパフォーマンス
・完全オフライン運用によるデータ漏洩リスクの低減
・完全なデータ制御によるコンプライアンス遵守の容易さ

注意点: ・初期設定や環境変数の調整が必要なため、設定方法を正確に把握する必要があります。
前提条件

ハードウェア要件
- CPU: 2コア以上のプロセッサが必要です。これにより、複雑なAI推論タスクを効率よく処理することができ、システム全体のパフォーマンスが向上します。特に、最適な運用例としては8コア以上のプロセッサが推奨されます。
- GPU/RAM: 16 GiB以上が推奨されます。高負荷なAI推論や複数のプロセスを同時に実行するシナリオでは、十分なメモリ容量が不可欠です。大規模なモデルを使用する際には、メモリ不足に陥ると計算処理が途中で停止する可能性があるため、16 GiB以上のRAMを用意することで、確実なパフォーマンスと安定性を確保できます。
これらのハードウェア要件を満たすことにより、DifyとDeepSeekの統合システムは、調査自動化アプリケーションとしての高い安定性とパフォーマンスを発揮することができ、複雑な計算処理にも対応可能な環境が提供されます。
ソフトウェア要件
- Docker: Dockerは、アプリケーション環境の構築と管理を効率化するための必須ツールです。複数のコンテナを用いた柔軟なシステム運用は、DifyとDeepSeekの統合を円滑に進める上で重要な役割を果たします。
- Docker Compose: コンテナのオーケストレーションを容易にするために不可欠なツールです。システム全体の構成が一元管理され、各コンテナ間の連携がスムーズに行えます。
- Ollama: Ollamaは、AIモデルのアプリストアとして機能し、多様な大規模言語モデルを簡単にデプロイできる利便性を提供します。クロスプラットフォームに対応しており、macOS、Windows、Linuxなど様々な環境での利用が可能です。
- Dify Community Edition: GitHubで公開されているオープンソースプロジェクトで、AIアプリケーション開発のためのオールインワンツールチェーンを提供します。Difyは、ローコード環境により非エンジニアでも簡単に操作でき、各種サードパーティツールとの統合が容易です。

これらのソフトウェア要件を正しくインストールし構成することで、DifyとDeepSeekをシームレスに連携させることができ、調査自動化システムを堅牢に運用するための基盤が整います。特に、オープンソースコミュニティによるサポートが充実しているため、トラブルシューティングや機能拡張も効率的に行えるようになります。
デプロイメントガイ

Ollamaのインストール
Ollamaは、AIモデルのアプリストアとして機能し、DeepSeek、Llama、Mistralなどの大規模言語モデルを容易にデプロイするためのツールです。まず、Ollamaの公式Webサイトにアクセスし、macOS、Windows、Linuxといった多様なプラットフォームに対応したクライアントをダウンロードしてください。ダウンロード後、インストール手順に従い、環境構築を進めます。インストールが完了したら、ターミナルまたはコマンドプロンプトを開き、以下のコマンドを実行して正しくインストールされたかを確認してください。
上記コマンドの実行結果として、たとえば「ollama version is 0.5.5」と表示されることで、正しくインストールされたことが確認できます。初期設定では、DeepSeek R1の7Bモデルの利用が推奨されています。この7Bは、トレーニングパラメータ数を示しており、パラメータが多いほど応答の精度や速度は向上しますが、一方でメモリの消費量も増加するため、システム環境に合わせた適切な選択が求められます。ユーザーは、システム環境に基づいて最適なモデルサイズを選定し、効率的なAI運用を目指してください。さらに、Ollamaを活用することで、デプロイ作業が単一のコマンドで実行でき、すべての使用データがローカルに保持されるため、データセキュリティも万全な体制が整えられます。
次に、ターミナルで以下のコマンドを実行して、DeepSeek R1の7Bモデルをインストールします。
Dify Community Editionのインストール
Difyは、AIアプリケーションを構築するためのオールインワンツールチェーンを提供するオープンソースプロジェクトです。GitHub上で公開されているこのプロジェクトは、ユーザーが簡単かつ迅速に独自のAIアプリケーションを作成できるよう、豊富なツールとドキュメントが整備されています。まず、Difyのリポジトリをクローンし、ローカル環境にダウンロードします。クローンが完了したら、Docker環境を整備した上で、提供されているDocker Composeファイルを使用し、コンテナを起動します。
これにより、システム全体が自動化された状態で稼働を開始できるため、初期設定が非常にスムーズに行われます。ユーザーは、各コンテナの状態をターミナル上で確認し、問題が発生した場合には、DockerまたはDocker Composeの設定を再確認することで、迅速に対処可能です。Dify Community Editionは、初期設定ではポート80を使用してプライベートシステムにアクセス可能となっており、必要に応じてWebアクセスポートの変更も可能となっています。これにより、セキュリティやネットワーク構成に応じた柔軟な設定が行え、ユーザーのニーズに合わせたカスタマイズが容易に実現できます。
git clone https://github.com/langgenius/dify.git cd dify/docker cp .env.example .env docker compose up -d 上記コマンドの実行により、必要なコンテナがすべて起動し、Difyプラットフォームが利用可能な状態となります。各コンテナのポートマッピングや実行ステータスはターミナルに表示されるため、問題が発生した場合のトラブルシューティングも容易です。
DeepSeekとDifyの統合
Difyプラットフォーム上でDeepSeekを統合する手順は、シンプルかつ直感的に設定できるよう設計されています。まず、Difyのユーザーインターフェース上部にあるプロファイル→設定→モデルプロバイダーをクリックし、Ollamaを選択します。次に、「モデルの追加」ボタンを押し、デプロイ済みモデルの詳細情報を入力します。具体的には、モデル名として「deepseek-r1:7b」を設定し、ベースURLにはOllamaクライアントが実行されているアドレス(通常は http://your_server_ip:11434)を入力します。
他のオプションはリライト元記事に示されるデフォルト値のままとし、最大トークン長は32,768トークンに設定しておくことで、より広範なデータを扱う際にシステムが柔軟に対応できるようにします。こうした設定により、AIモデルはDifyプラットフォームとシームレスに連携し、ユーザーがチャットボットやその他のAIアプリケーションを利用する際に高品質な応答を生成できるようになります。設定後は、Dify上でモデルの動作確認を行い、正しく連携されているかどうかを検証することが重要です。確認作業を終えた後に、ユーザーはこれらの設定を元に実際のAIアプリケーションを構築していくことができ、調査自動化のプロセスが大幅に効率化されます。
AIアプリケーション構築の開始

DeepSeek AIチャットボット(シンプルなアプリケーション)
プライベートに稼働するAIアシスタントが構築された後、シンプルなチャットボットアプリケーションを作成する手順は、非常にわかりやすく設計されています。まず、Difyのホームページ左側のサイドバーにある「空白のアプリを作成」をクリックし、表示されるオプションからチャットボットタイプを選択し、アプリケーションに適切な名前を付けます。これにより、AIチャットボットが基盤として自動的に初期設定され、ユーザーは直感的にチャットボットのインターフェースにアクセスすることができます。続いて、右上の「アプリケーションタイプセレクター」から、Ollamaフレームワークのdeepseek-r1:7bモデルを選択します。
これにより、チャットボットが最新のAIモデルを利用して、ユーザーからのメッセージに対して迅速かつ適切な応答が返される仕組みが整います。さらに、チャットプレビューウィンドウにテストメッセージを入力し、AIの応答が正確かつタイムリーに表示されるかを確認するプロセスを経て、アプリケーションの動作確認が完了します。公開ボタンをクリックすると、アプリのリンクが生成され、他のWebサイトでの共有や埋め込みが可能となります。
その後、右上のアプリケーションタイプセレクターから適切なモデルを選択した後、チャットウィンドウに実際のユーザー入力を試し、AIの反応を確認する手順が設けられています。このプロセスにおいて、応答の正確性、タイムリーさ、及び文脈対応能力が確認されることで、システム全体の信頼性が担保され、ユーザーは安心してアプリケーションを公開できる状態となります。最終確認が完了した段階で、公開ボタンをクリックし、生成されたリンクによって、アプリケーションの共有や外部サイトへの埋め込みが容易に実現される点も大きな魅力といえます。
DeepSeek AIチャットボット+ナレッジベース
大規模言語モデルが抱える課題のひとつに、トレーニングデータがリアルタイムで更新されず、結果として「幻覚」とも呼ばれる不正確な応答が生じるという点があります。これを改善するために、Retrieval-Augmented Generation (RAG)の技術を用い、関連する情報がモデルの応答に適切に反映される仕組みを導入します。まず、内部ドキュメントや専門資料をアップロードしてナレッジベースを作成します。
このプロセスでは、親子チャンクモードを使用することで、ドキュメントの論理的な構造や階層情報を正確に保持し、情報の抜け漏れを防止します。ナレッジベースの構築後、AIアプリの「コンテキスト」セクションにこれを統合し、ユーザーからの各種問い合わせに対して、該当する情報を自動で参照できる状態を作り上げます。システムはまずナレッジベース内から関連するコンテキストを取得し、その情報をもとに要約を生成することで、より精度の高い回答を返す仕組みとなっています。
また、RAGの手法によって、AIの応答が内蔵された知識を背景にして行われるため、従来の方法に比べ、より信頼性の高い応答が可能となります。こうした統合により、情報の更新遅延や不正確な回答のリスクが大幅に軽減され、実際の業務フローにおける精度と効率が飛躍的に向上することが期待されます。実際の運用例では、組織内の知識管理システムと連携して、常に最新の情報をAIチャットボットが参照できるようになっており、ユーザーの問い合わせに対し、タイムリーかつ正確な情報提供が実現される仕組みが整っているのです。
さらに、AIアプリの画面上にナレッジベース統合用のコンテキスト領域が設けられており、ユーザーからのクエリに対して、AIが関連情報を抽出・要約する処理が実施されます。これにより、結果として、チャットボットの応答の正確性が向上し、業務上の意思決定支援ツールとしても高い効果を発揮するものとなっています。こうした統合策は、常に最新の業務情報を参照した上での回答を促し、従来の静的な回答システムでは得られなかった柔軟性とリアルタイム性をもたらします。

DeepSeek AIチャットフロー/ワークフロー(Web検索)
より高度なソリューションとして、Web検索、ファイル認識、音声認識など、さまざまな機能を統合したチャットフローやワークフローを構築することが可能です。ここでは、DeepSeekのWeb検索機能を有効にする方法について詳述します。ユーザーはまず、Difyのホームページ左側のサイドバーから「空白のアプリを作成」を選ぶことで、チャットフローまたはワークフローの新規作成を開始します。その後、Web検索ノードを追加し、取得したSerpApiのAPIキーを設定、同時に初期ノードから提供される{{#sys.query#}}変数を活用して、ユーザークエリを正確に反映させる仕組みを構築します。次に、コード実行ノードを追加し、取得されたJSON形式の検索結果から必要な情報を抽出するためのカスタムスクリプトを挿入します。スクリプトは、各検索結果のタイトル、リンク、スニペットを連結して1つの結果文字列を生成し、最終的にその結果を出力します。
これにより、検索結果が整理された形でAIに提供され、より精度の高い応答生成が実現されます。さらに、LLMノードをOllamaフレームワークのdeepseek-r1:7bモデルで設定し、システムプロンプト内に同じく{{#sys.query#}}変数を挿入することで、ユーザーの入力に応じた最適な回答を生成できる仕組みとなっています。各ステップにおいて、エラー処理やロードバランシングの設定を採用することで、実運用環境における例外処理やシステムの安定性が確保されています。最後に、LLMノードからのアウトプットを終了ノードで参照し、全体のプロセスが正しく実行されるかを確認しながら、システム全体のテストを実施します。こうして構築されたWeb検索を活用したチャットフローは、ユーザーが求める最新情報をリアルタイムに取得し、即応的に回答を生成するための強力なソリューションとなります。
DifyはWeb検索連携や複雑なワークフロー構築など、非常に高機能なプラットフォームです。しかし、ここまで多機能になると「何から手を付けるべきか」「自社業務にどこまで適用するか」で悩む企業様も多いはずです。
私たちのDify導入支援サービスなら、御社の状況に合わせた最適解をご提案し、開発や運用をトータルで支援します。「これ、もう任せたいかも…」と思ったら、ぜひ一度ご相談ください!
FAQ

Docker使用時の接続エラー
このエラーは、Dockerコンテナ内のlocalhostがコンテナ自身を参照するため、Ollamaにアクセスできないことが原因です。
Macの場合: launchctl setenv OLLAMA_HOST "0.0.0.0"を実行し、Ollamaを再起動します。
Docker内でホストに接続する場合は、localhostの代わりにhost.docker.internalを使用してください。
Linuxの場合: systemctl edit ollama.serviceを実行し、[Service]セクションに Environment="OLLAMA_HOST=0.0.0.0" を追加後、systemctl daemon-reloadとsystemctl restart ollamaを実行します。
Windowsの場合:
ユーザーおよびシステム環境変数からOLLAMA_HOSTやOLLAMA_MODELS等を設定し、Ollamaを再起動してください。
Ollamaサービスのアドレスとポートを変更する方法
Ollamaはデフォルトで127.0.0.1のポート11434にバインドされています。OLLAMA_HOST環境変数を使用してバインドアドレスを変更することが可能です。例えば、OLLAMA_HOSTを0.0.0.0に設定し、サービスを再起動することで、新しいアドレスとポート設定を反映させることができます。これにより、Dockerやその他の環境における接続エラーを防止し、システム全体の安定稼働が実現されます。
まとめ

本記事では、DifyとDeepSeekを用いたプライベートな調査自動化システムの構築方法について解説しました。以下に、本構築方法の主なポイントをまとめます。
- 多様なAIモデルへの柔軟なアクセス: 1000以上のモデルに対応し、業務に応じた最適なモデルを選択可能。
- 高いパフォーマンス: 商用グレードの安定した応答速度と、8コア/32GiB以上のシステムで定量的なメリットを実現。
- 完全なオフライン環境: ネットワーク経由のデータ漏洩リスクを排除し、セキュリティを確保。
- データの完全制御: ローカルでの管理によりコンプライアンス遵守と柔軟なカスタマイズが可能。
- 容易なデプロイメント: OllamaやDify Community Editionを利用したシンプルなセットアップと運用が実現。
- 注意点: 初期設定や環境変数の調整が必要なため、手順を正確に把握することが求められます。
以上の内容を参考に、最適なシステム環境の構築と運用を進め、調査自動化の効率化、安全性、信頼性の向上を目指してください。

